WHY
지금 뛸지, 조금 기다릴지 더 쉽게 판단할 수 없을까? 좋은 러닝 시간은 맑거나 선선한 시간과 달랐습니다. 공기질과 열 부담처럼 성격이 다른 신호를 함께 봐야 했습니다.
애플리케이션 개발
WHY
지금 뛸지, 조금 기다릴지 더 쉽게 판단할 수 없을까? 좋은 러닝 시간은 맑거나 선선한 시간과 달랐습니다. 공기질과 열 부담처럼 성격이 다른 신호를 함께 봐야 했습니다.
HOW
건강 리스크와 체감·퍼포먼스 부담을 나눠 보았습니다. 여러 수치를 그대로 나열하지 않고, 지금 뛰어도 되는지 혹은 기다리는 게 나은지를 시간대별 판단으로 묶었습니다.
WHAT
Running Condition Score 기반의 러닝 판단 앱을 만들고 있습니다. 시간대별 조건과 판단 이유를 함께 보여주고, 홈 화면과 아이콘까지 ‘지금 달릴 시간인가’를 먼저 읽게 다듬고 있습니다.
2026-05-11
러닝을 마치고 나서야 그 시간의 초미세먼지가 좋지 않았다는 걸 알았다. 뛰는 동안에는 크게 이상하지 않았다. 더 아쉬운 건 몇 시간만 기다렸다면 조건이 나아질 수 있었다는 점이었다.

뛰고 나서야 “아, 오늘은 좀 기다릴 걸” 싶어지는 순간. GIF via
GIPHY / Zhot
.
그때의 불편은 단순히 정보를 확인하지 않았다는 문제가 아니었다. 러닝 전에 앱을 몇 개 더 열어볼 수도 있고, 미세먼지 수치를 따로 볼 수도 있다. 하지만 실제로 알고 싶었던 건 수치 하나하나가 아니었다.
오늘 몇 시쯤 달리는 게 가장 좋을까?
이 질문이 달릴시간의 출발점에 가까웠다. 오늘 달릴지 말지, 달린다면 지금이 나은지 조금 기다리는 게 나은지, 나중으로 미루면 실제로 더 좋은 조건이 되는지 알고 싶었다.
러닝 조건을 어렵게 만드는 요소들은 서로 성격이 달랐다. 초미세먼지처럼 몸으로 바로 느끼기 어렵지만 주의 깊게 봐야 하는 요소가 있고, 습도나 WBGT처럼 같은 페이스를 더 무겁게 만드는 요소도 있다. 바람은 페이스와 피로도에 영향을 주고, UV는 퍼포먼스보다 노출 부담에 가깝다.
그래서 이 요소들을 모두 같은 방식으로 보면 이상해진다. 어떤 요소는 조금만 나빠도 조심해야 하고, 어떤 요소는 다른 조건과 함께 볼 때 부담이 커진다. 러너에게 필요한 판단은 단순 평균이 아니라, 공기질처럼 주의가 필요한 조건과 체감·퍼포먼스 부담을 구분해서 읽는 쪽에 더 가까웠다.
달릴시간이 만들고 싶었던 것도 바로 그 지점이었다. 환경 수치를 많이 보여주는 앱이 아니라, 러너가 오늘의 실행 타이밍을 더 쉽게 판단하도록 돕는 앱. 지금 뛰어도 되는지, 조금 기다리는 게 나은지, 오늘 중 언제가 더 나은지를 먼저 읽게 하는 앱이었다.
Running Condition Score는 그 질문을 다루기 위한 하나의 표현 방식이었다. 숫자 하나로 모든 것을 단순화하려는 게 아니라, 여러 환경 조건을 러너의 판단 단위로 다시 묶어보려는 시도였다.
처음부터 완성된 알고리즘이 있었던 것은 아니다. 오히려 반대였다. 어떤 요소를 주의 신호로 볼지, 어떤 요소를 체감 부담으로 볼지, 어떤 조건에서는 조심해야 한다고 말해야 할지 계속 나눠 봐야 했다.
이 프로젝트의 첫 질문은 그래서 “좋은 날씨를 어떻게 보여줄까”가 아니었다. 더 정확히는, 러너가 앱을 열었을 때 이런 답을 먼저 받을 수 있느냐였다.
지금 달려도 괜찮은가.
아니면 조금 기다리는 편이 나은가.
달릴시간은 좋은 날씨를 보여주기 위해 시작한 앱이 아니었다. 러닝을 마친 뒤 “조금만 기다릴 걸”이라고 말하는 시간을 줄이기 위해 시작했다.
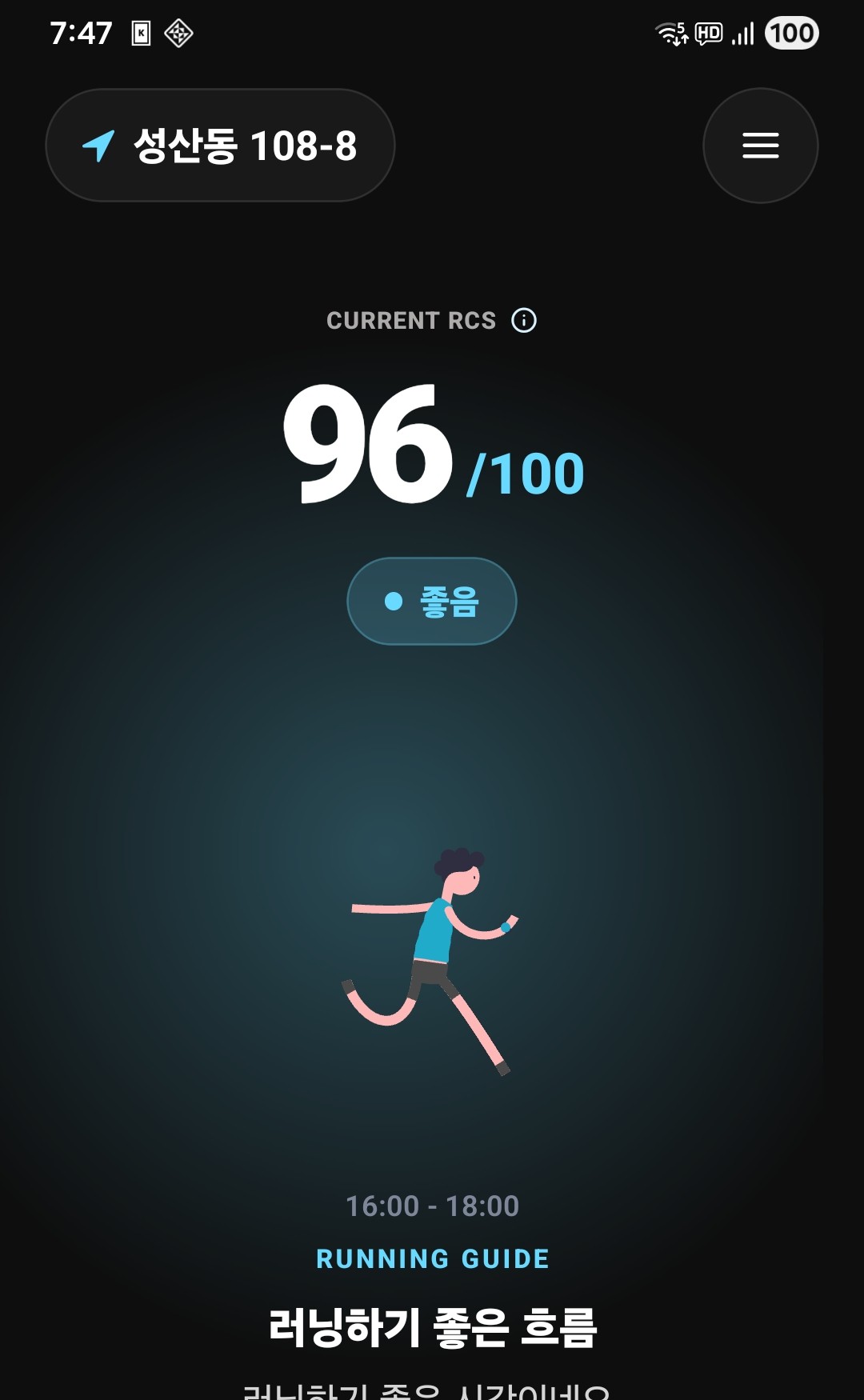
달릴시간의 첫 화면은 여러 수치를 나열하기보다, 지금 달릴지 조금 기다릴지를 먼저 판단하게 만드는 방향으로 잡았다.
2026-05-11
평균은 깨끗했다. 답은 위험했다.
초미세먼지가 높은 날이었다. 기온은 괜찮고 바람도 나쁘지 않았다. 모든 값을 점수로 바꿔 평균을 냈더니 “달리기 좋음”에 가까운 숫자가 나왔다. 계산은 틀리지 않았다. 그런데 그 숫자를 믿고 밖으로 나가라고 말할 수는 없었다.
숫자를 한 줄로 세우는 순간, 서로 다른 위험이 같은 표정을 짓기 시작했다.

다 같은 숫자로 바꿨다고 해서 바로 평균낼 수 있는 건 아니었다. GIF via
GIPHY / GifGari
.
러닝 조건은 모두 같은 신호가 아니었다. 초미세먼지는 뛰는 동안 바로 힘들게 느껴지지 않아도 주의해야 한다. 습도와 WBGT는 몸이 느끼는 부담에 더 가깝고, 바람은 페이스와 피로도를 흔든다. UV는 퍼포먼스보다 노출 부담에 가깝다.
이들을 똑같이 깎는 것은 자동차의 브레이크와 승차감을 한 점수로 평균내는 것과 비슷했다. 승차감이 좋아도 브레이크가 고장 났다면 “대체로 괜찮은 차”라고 말할 수 없다. 반대로 보조 신호까지 모두 강하게 깎으면, 조심해서 달릴 수 있는 시간도 사라진다.
그래서 달릴시간의 점수는 예쁜 평균값보다 일관되고 설명 가능한 판단이어야 했다. 어떤 요소는 점수를 직접 크게 제한하고, 어떤 요소는 보조적으로만 반영하고, 어떤 요소는 점수보다 설명에서 더 잘 다뤄야 했다.
| 요소 | 앱에서 본 역할 | 처리 방향 |
|---|---|---|
| 초미세먼지 PM2.5 | 체감이 약해도 주의가 필요한 공기질 신호 | 주요 기준으로 강하게 반영 |
| PM10 | 독립 주지표보다는 보조 공기질 신호 | modifier로 반영 |
| WBGT / 열 부담 | 같은 페이스를 더 힘들게 만드는 신호 | 열 스트레스 판단에 반영 |
| UV / 바람 / 습도 | 상황에 따라 부담을 키우는 보조 신호 | 단독으로 과하게 무너뜨리지 않음 |
| 강수 / 천둥 | 실행 가능성과 안전 문제 | 강한 제한 또는 blocker |
이 구분이 없으면 앱은 숫자를 많이 계산해도 러너에게는 덜 믿기는 답을 줄 수 있었다.

달릴시간은 모든 환경 지표를 똑같이 깎지 않고, 러너가 대처할 수 있는 부담과 피하기 어려운 부담을 나눠 설명한다.
특히 초미세먼지는 따로 다뤄야 했다. 달리면서 바로 체감되지 않을 수 있다는 점 때문에 더 그렇다. 몸이 괜찮다고 느끼는 것과 실제 노출 부담가 낮다는 것은 같지 않다.
그래서 RCS v1에서는 PM2.5를 primary factor로 두고, 일정 구간 이상에서는 하루 점수의 상한을 제한하는 guardrail을 뒀다.
PM2.5가 하루 절반 이상 지속될 때의 day score 상한
25-35 → 최대 69
35-50 → 최대 54
50+ → 최대 39좋은 두 시간이 나쁜 하루를 세탁하지 못하게 만든 셈이다. 이 상한은 두 가지를 막기 위한 장치였다.
달릴시간이 알려주고 싶은 것은 “가장 좋은 숫자 하나”가 아니라, 오늘 남은 시간 안에서 실제로 달릴 만한 선택지가 있는지였다.
또 하나의 문제는 시간대였다. 한두 시간만 조건이 좋아도 오늘의 best time은 있을 수 있다. 하지만 그 짧은 구간 하나 때문에 하루 전체를 좋게 말하면 안 된다.
그래서 day score는 단순 평균이 아니라 세 가지를 함께 보도록 잡았다.
best 2-hour rolling average 55%
remaining-hour coverage >= 70 25%
median remaining-hour score 20%완벽한 정답은 아니었다. 당시 앱이 가져야 할 첫 번째 판단 기준이었다. 반짝 좋은 구간은 추천하되, 그 한 조각으로 하루 전체를 포장하지 않으려는 시도였다.
RCS를 만들면서 계속 조심해야 했던 것은 숫자가 모든 설명을 대신하게 만드는 일이었다. 점수는 빠르게 읽히는 입구가 될 수 있지만, 사용자가 믿으려면 왜 그런 점수가 나왔는지도 이어져야 한다.
그래서 Home hero에는 점수와 한 줄 해석이 필요했고, 그 아래에는 Best Time과 상세 근거가 필요했다. 어떤 날은 PM2.5가 핵심 이유가 되고, 어떤 날은 열 부담이나 강수 가능성이 더 중요해진다. 점수 하나는 같아도 이유는 다를 수 있다.
달릴시간의 두 번째 고민은 여기 있었다.
같은 60점이라도, 왜 60점인지 설명할 수 있어야 했다.
이 지점에서 앱은 단순히 숫자를 계산하는 쪽에서 벗어나기 시작했다. 공기질처럼 주의가 필요한 조건과 체감 부담을 나눠 보고, 시간대별로 다시 묶고, 그 결과를 사용자가 읽을 수 있는 말로 바꾸는 일이 필요해졌다.
달릴시간에 필요했던 것은 평균을 잘 내는 계산기가 아니었다. 위험을 다른 좋은 조건 속에 숨기지 않는 계산이었다.
2026-05-11
임시 폴더가 사라졌다. 그 안에는 달릴시간의 코드와 판단 기록 일부가 있었다.
파일을 잃었으니 파일을 복구하면 된다고 생각하기 쉽다. 실제로 더 오래 걸린 것은 따로 있었다. 되살아난 여러 버전 가운데 무엇이 지금의 앱인지, 어느 판단부터 다시 이어가야 하는지 알 수 없었다.
지도는 찾았는데 “현재 위치” 표시가 지워진 셈이었다.
파일 하나가 아니라 이어가던 기준 자체가 흐려지는 순간. GIF via
GIPHY / WizArt
.
처음에는 당연히 복구가 먼저라고 생각하기 쉽다. 하지만 실제로는 파일을 되살리는 일만으로는 충분하지 않았다. 이전 후보가 어떤 판단을 했는지, 현재 앱이 어느 빌드를 기준으로 움직이는지, 사용자가 보게 될 화면이 어느 흐름의 결과물인지가 함께 정리되어야 했다.
그래서 질문은 “어떻게 빨리 다시 만들까?”에서 조금 바뀌었다.
무엇을 현재 truth로 볼 것인가?
무엇은 archive로만 남길 것인가?
어떤 판단은 다시 검증한 뒤에만 가져올 것인가?이 구분이 없으면 같은 기능을 다시 만들어도, 다음 QA에서 또 다른 기준을 보고 판단하게 된다. 특히 달릴시간처럼 점수·화면·설명·릴리즈 빌드가 함께 맞아야 하는 앱에서는 이 차이가 작지 않았다.
이후에는 본선 개발과 PM reset 흐름을 분리해서 보기 시작했다. 하나는 실제 앱을 앞으로 밀고 가는 자리였고, 다른 하나는 사라진 판단과 남은 근거를 다시 읽어 현재 기준을 재구성하는 자리였다.
절차가 늘어난 것처럼 보였지만 실제로는 반대였다. 본선 개발 안에서 복구와 검증과 기록을 모두 섞어두면, 무엇이 제품 결정이고 무엇이 임시 수습인지 금방 흐려졌다.
그래서 달릴시간에서는 한동안 다음과 같은 구분이 필요했다.
이 구분을 세우고 나서야, 다음 기능을 붙이는 일이 조금 덜 불안해졌다.
이 경험은 제품 자체의 기능은 아니지만, 이후 작업 방식에는 꽤 큰 영향을 줬다. 달릴시간은 단순한 화면 앱이 아니라 판단 모델을 계속 조정해야 하는 앱이었다. 그렇다면 코드만큼이나 “왜 이 판단을 했는지”도 함께 남아 있어야 했다.
특히 러닝 조건 점수처럼 미세한 보정이 쌓이는 영역에서는, 과거 결정을 잃어버리면 같은 논의를 반복하기 쉽다. PM2.5를 얼마나 강하게 볼지, WBGT를 언제부터 기본 기준으로 볼지, 바람과 강수를 어디까지 제한할지 같은 질문은 코드보다 판단의 맥락이 더 중요할 때가 많았다.
이후의 달릴시간 작업은 조금 느려졌고 더 명시적이 됐다. 기능을 붙이기 전에 현재 truth, 바꾸는 판단, 채택 근거, 보류한 후보부터 적었다. WBGT도 계산식보다 역할을 먼저 정했다.
코드가 사라진 날, 달릴시간은 파일 복구법보다 기준을 남기는 법을 먼저 배웠다.
2026-05-11
온도계는 둘 다 27도를 가리켰다. 한 번의 러닝은 버틸 만했고, 다른 한 번은 같은 페이스가 유난히 무거웠다.
습도, 바람, 햇볕, 복사열이 몸이 받는 부담을 바꿨다. “덥다”를 숫자로 보여주는 것과 “지금 달릴지 조금 기다릴지”를 판단하는 일은 달랐다.
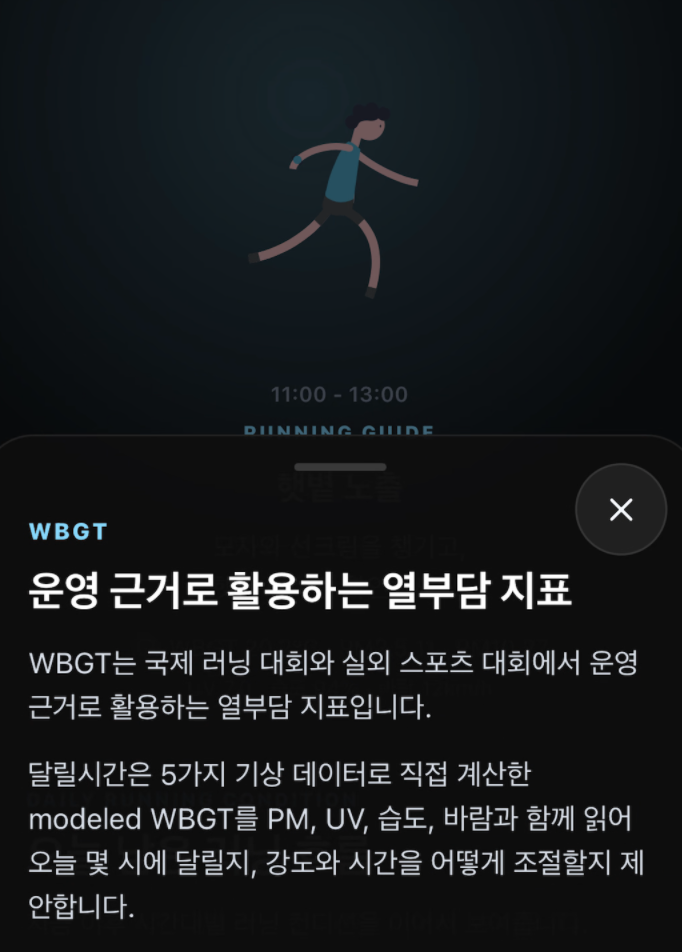
WBGT는 낯선 숫자로 앞세우기보다, 왜 더위 부담을 다르게 봐야 하는지 설명하는 근거로 들어가야 했다.
WBGT는 Wet Bulb Globe Temperature의 약자로, 단순 기온보다 열 부담을 더 입체적으로 보려는 지표다. 야외 활동과 스포츠 환경에서 열 스트레스 판단에 참고되는 이유도 여기에 있다. 달릴시간에서는 이 지표를 그대로 권위처럼 가져오고 싶었던 것은 아니었다. 다만 러너에게 필요한 질문은 분명했다.
오늘 몇 시가 덜 위험하고,
덜 힘들고,
그래도 달릴 만한 시간인가?기온 하나만 보면 이 질문에 답하기 어려웠다. 습도와 바람, 햇볕의 영향이 빠지면 실제 러닝 부담과 앱의 판단이 어긋날 가능성이 컸다. 그래서 WBGT는 더위를 더 잘 설명하기 위한 후보가 되었다.
그렇다고 WBGT를 바로 기본값으로 넣을 수는 없었다. 우선 데이터가 문제였다. 모든 지역에서 바로 쓸 수 있는 신뢰도 높은 직접 WBGT 데이터가 있는 것은 아니었고, 앱이 이미 쓰고 있던 Open-Meteo 기반 입력값으로 모델링할 수 있는 범위와 한계를 따져야 했다.
또 하나는 설명의 문제였다. 사용자는 WBGT라는 단어를 처음 볼 수 있다. 앱이 갑자기 낯선 지표를 앞세우면 “정확해 보인다”보다 “이게 뭐지?”가 먼저 올 수 있다. 그래서 내부 모델에서는 열 부담을 더 잘 보되, 화면에서는 러너가 이해할 수 있는 문장과 근거로 풀어야 했다.
이때 기준은 세 가지였다.
WBGT는 이 기준을 통과해야 했다. 지표를 추가하는 것보다 중요한 것은, 지표가 앱의 판단을 더 믿을 만하게 만드는지였다.
화면에서는 모든 지표를 같은 감점으로 다루지 않고, 러너가 실제로 대응할 수 있는 부담인지까지 함께 설명해야 했다.
결국 WBGT는 단순히 점수 하나를 더하는 일이 아니었다. 홈 화면, 일별 상세, 정보 시트, 법적 고지, QA 기준까지 이어지는 사용자가 근거를 읽을 수 있는 화면의 문제였다. 앱 안에서 “WBGT를 보고 있다”고 말하려면, 실제 화면의 근거도 그 방향으로 정렬되어야 했다.
그래서 이후 작업은 WBGT v2를 후보로 붙이고, 실제 위치 기준으로 확인하고, Daily detail과 Home hero가 같은 근거를 말하도록 맞추는 방향으로 이어졌다. 이 과정에서 낡은 기온/체감 중심 설명이 남아 있으면 오히려 신뢰가 깨졌다.
달릴시간이 WBGT를 넣은 것은 과학적인 이름을 하나 더 보여주기 위해서가 아니었다. 기온 하나로 설명되지 않는 더위를 인정하고, 러너에게 조금 덜 틀린 시간을 말하기 위해서였다.
2026-05-11
60점이 나왔다. PM2.5 때문인지, 열 부담 때문인지, 비 때문인지는 보이지 않았다.
점수는 빠르게 읽혔지만 다음 행동까지 말해주지 못했다. 달릴시간은 숫자를 더 정교하게 만드는 대신, 같은 화면 안에서 왜 지금이 좋거나 왜 기다려야 하는지 설명하기 시작했다.
홈 화면은 점수만 보여주는 표면이 아니라, 지금 판단과 그 이유로 들어가는 입구가 되어야 했다.
예를 들어 같은 60점이라도 이유는 다를 수 있다. 어떤 날은 초미세먼지가 높아서 조심해야 하고, 어떤 날은 WBGT가 높아서 열 부담이 크고, 어떤 날은 비나 바람 때문에 실행 가능성이 떨어진다. 숫자만 보면 비슷하지만 사용자가 취해야 할 행동은 달라질 수 있다.
그래서 홈 화면에는 점수와 캐릭터만 둘 수 없었다. 지금 뛰어도 되는지, 기다리면 나아지는지, 어떤 근거로 그렇게 말하는지를 함께 보여줘야 했다. 홈은 점수판에서 판단의 이유를 읽는 화면으로 바뀌었다.
이때 정리한 방향은 비교적 단순했다.
1. 지금 바로 읽을 수 있는 결론
2. 그 결론을 만든 핵심 근거
3. 시간이 지나면 달라지는지 보는 다음 행동이 구조가 있어야 사용자는 앱의 판단을 그대로 외우는 대신, 자기 상황에 맞춰 받아들일 수 있다.
또 하나의 문제는 화면 사이의 일관성이었다. 홈에서는 WBGT와 PM을 중심으로 말하는데, 상세 화면에 들어가면 다시 낡은 기온·체감 중심 설명이 나오면 사용자는 금방 헷갈린다. 앱 내부에서는 새 판단 모델을 쓰고 있는데, 화면 일부가 예전 언어를 계속 말하는 상태가 되는 것이다.
그래서 Daily detail도 Home hero와 같은 근거 모델을 말하도록 맞췄다. WBGT, PM2.5, PM10, UV, 습도, 바람이 서로 다른 역할로 읽히고, 사용자가 특정 시간대를 눌렀을 때도 같은 판단 구조가 이어지도록 했다.
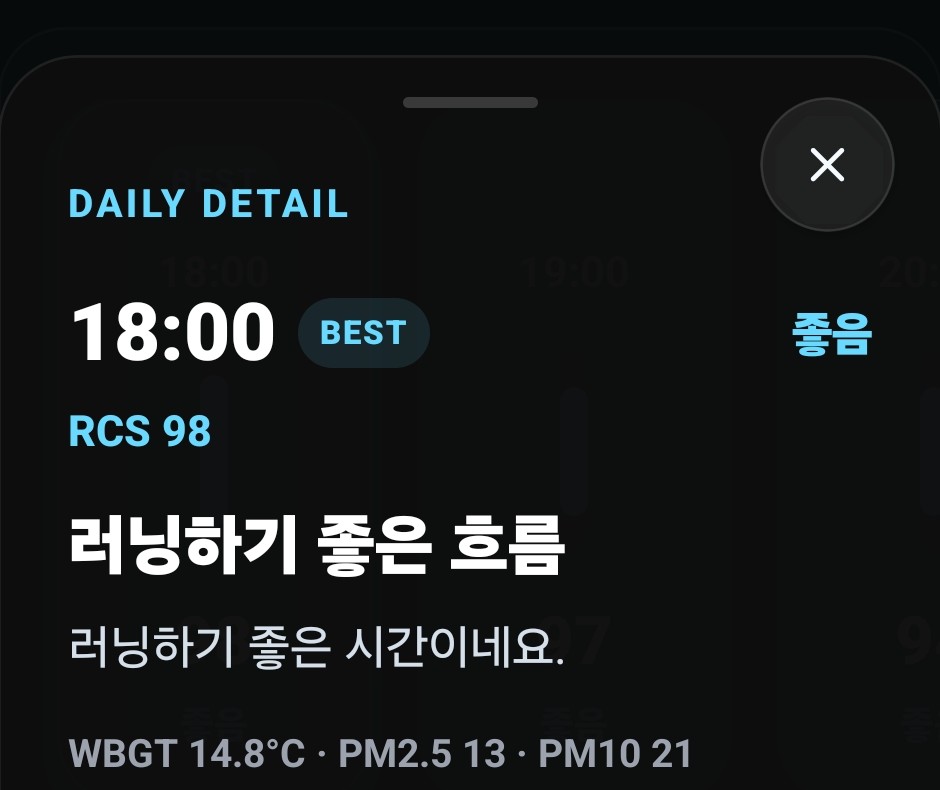
상세 화면에서도 홈과 같은 근거를 말해야, 사용자는 점수보다 판단 구조를 믿을 수 있었다.
이 작업은 UI 문구 수정처럼 보일 수 있지만, 실제로는 신뢰를 맞추는 일이었다. 같은 앱 안에서 서로 다른 기준이 말하면, 사용자는 어느 쪽을 믿어야 하는지 모르게 된다.
점수와 이유를 맞추기 시작하자 QA 기준도 달라졌다. 화면이 보인다는 것만으로는 충분하지 않았다. 실제 위치에서 Home, Daily detail, 정보 시트, 모델 입력값이 같은 방향을 가리키는지 확인해야 했다. 오래된 빌드나 중간 후보가 섞이면, 잘못된 화면을 보고 맞다고 판단할 수도 있었다.
그래서 달릴시간의 후반 작업은 기능 추가보다 기준 맞추기에 가까웠다. 어떤 빌드가 현재 기준인지, 어떤 후보가 release default인지, 어떤 화면이 아직 legacy 설명을 갖고 있는지 하나씩 확인했다.
점수는 판단의 시작점일 뿐이었다. Home과 Daily detail이 같은 이유를 말하고 실제 위치의 입력값까지 같은 방향을 가리킬 때 비로소 숫자가 제품의 언어가 됐다. 60점을 믿게 만든 것은 60이라는 숫자가 아니라, 그 뒤에서 한목소리로 말하는 화면들이었다.
2026-05-11
후보 보드에서는 어두운 아이콘이 가장 완성돼 보였다. 실제 아이폰 홈에 올리자 다른 앱 사이로 사라졌다.
아이콘은 단독 이미지가 아니라 매일 손가락이 찾는 배포 표면이었다. 질문을 “가장 예쁜가?”에서 “많은 앱 사이에서 바로 보이는가?”로 바꿨다.
후보들을 나란히 놓고 보면 완성도 차이가 보였지만, 이것만으로는 실제 선택을 끝낼 수 없었다.
아이콘 후보를 만드는 과정에서는 여러 방향을 시험했다. 신발과 시계 조합, 추상적인 속도/시간 마크, 러너가 시계 링 안에 들어간 형태, 어두운 네이비/틸 계열의 프리미엄한 버전, 손목의 빛이나 러너의 자세를 강조한 버전까지 있었다.
그중 일부는 단독 이미지로 보면 더 그럴듯했다. 하지만 앱 아이콘은 갤러리에 걸리는 이미지가 아니라, 사용자의 홈화면에 놓이는 작은 표면이다. 크기가 줄어들고, 다른 앱과 섞이고, 배경이 밝거나 어두워질 때도 살아남아야 했다.
그래서 판단 기준은 조금씩 바뀌었다.
브랜드 톤과 잘 맞는가
→ 작은 크기에서도 러너와 시간이 읽히는가
→ 실제 홈화면에서 눈에 들어오는가이 변화가 중요했다. 달릴시간은 사용자가 “오늘 몇 시에 달릴까?”를 떠올릴 때 바로 열어야 하는 앱이다. 그렇다면 아이콘도 조용히 예쁜 것보다, 순간적으로 찾기 쉬운 쪽이 더 맞았다.
결정적인 장면은 실제 아이폰 홈화면에 후보를 올려놓고 본 순간이었다. 어두운 후보는 앱 내부 UI와는 잘 어울렸지만, 홈화면에서는 생각보다 묻혔다. 특히 다크 배경이나 다른 강한 앱 아이콘 사이에서는 존재감이 약했다.
반대로 밝은 피치 계열 배경의 러너 아이콘은 조금 덜 프리미엄해 보일 수는 있었지만, 훨씬 빨리 보였다. 러너가 있고, 손목 쪽 빛이 있고, “달릴 시간”을 확인하는 느낌도 더 직접적이었다.
최종 판단은 후보 보드가 아니라 실제 홈화면 위에서 더 선명해졌다.
이 과정에서 배운 것은 간단했다. 아이콘은 브랜드 자산이지만 동시에 배포 표면이다. 앱을 설치한 사람이 매번 찾고 누르는 위치에 놓이기 때문에, 단독 이미지의 완성도만으로는 부족했다.
그래서 최종 선택은 “가장 멋진 아이콘”이라기보다 “테스터가 실제로 찾기 쉬운 아이콘”에 가까웠다. 어두운 버전이 더 정제되어 보이는 순간도 있었지만, 달릴시간의 첫 외부 테스트 기준에서는 밝은 러너 아이콘이 더 맞았다.
달릴시간은 날씨를 많이 보여주는 앱이 아니라 러너가 지금 실행할지 판단하게 돕는 앱이다. 아이콘도 설명보다 먼저 그 행동을 불러야 했다. 가장 멋진 후보 대신, 달릴 시간을 떠올린 순간 가장 먼저 찾을 수 있는 후보를 골랐다.
2026-05-14
제주에는 비가 꽤 왔다. 달릴시간의 현재 점수와 하루 흐름은 너무 괜찮아 보였다.
비 점수를 더 깎기 전에 확인할 것이 있었다. 앱이 지금 이 위치의 날씨를 제대로 보고 있는가였다. 틀린 입력에 정교한 감점을 얹어도 답은 틀린 채로 남는다.

비가 오는데 앱이 괜찮다고 말하는 순간, 문제는 점수보다 신뢰가 된다. GIF via
GIPHY / Eddsworld
.
처음에는 강수 감점을 더 키우거나, 비가 올 때 점수 상한을 더 낮추면 될 것처럼 보였다. 물론 그런 정책도 필요하다. 하지만 그보다 앞에 있는 질문이 있었다.
앱은 지금 어떤 데이터를 보고 “달려도 괜찮다”고 말하고 있는가?
기존 구조에서 Open-Meteo는 중요한 기본 데이터였다. 전 세계 위치를 다룰 수 있고, 다른 출처가 불안정할 때 대체 데이터로도 유용했다. 하지만 한국에서 먼저 쓰는 러닝 앱이라면 현재 비와 가까운 시간대 예보, 미세먼지 관측값은 한국에서 제공되는 출처를 먼저 봐야 했다.
그래서 방향은 점수 공식을 조금 고치는 쪽에서, 데이터 출처를 다시 세우는 쪽으로 이동했다.
새 구조에서는 한국 위치에 대해 기상청과 AirKorea를 더 앞에 두었다. 기상청 초단기실황과 초단기예보는 지금부터 가까운 시간대의 비, 바람, 습도, 낙뢰 같은 신호를 본다. AirKorea는 가까운 측정소의 PM2.5와 PM10을 본다. Open-Meteo는 없애지 않고, 대체 데이터와 UV/WBGT 보조 데이터로 남겼다.
한국 위치의 러닝 판단
→ 기상청: 현재/근접 시간대 비와 바람
→ AirKorea: 측정소 기반 미세먼지
→ Open-Meteo: 대체 데이터 + UV/WBGT 보조
→ Running Condition Score핵심은 데이터를 더 많이 붙이는 것이 아니었다. “오늘 달려도 되는가”라는 질문에 더 가까운 데이터를 먼저 보게 만드는 일이었다.
| 데이터 | 앱에서 맡은 역할 |
|---|---|
| 기상청 초단기실황 | 지금 비가 실제로 오는지 확인한다 |
| 기상청 초단기예보 | 앞으로 몇 시간의 강수와 바람을 보강한다 |
| AirKorea 측정소 | 국내 PM2.5 / PM10 값을 우선 반영한다 |
| Open-Meteo | 해외 위치, 장애 상황, UV/WBGT 보조로 남긴다 |
이렇게 바꾸고 나서야 Running Condition Score(RCS)는 단순한 계산식이 아니라, 출처가 있는 판단에 가까워졌다.
데이터 출처를 바꿨다고 바로 끝난 것은 아니었다. 실제로 한국 여러 지역에서 데이터가 어떻게 들어오는지 확인해야 했다. 제주, 서울·경기, 미세먼지 민감 지역, 남부·동해안·산간·섬 지역까지 19개 위치를 샘플링했다.
구현 과정에서는 AI를 코드 작성 속도를 높이는 보조 도구로도 썼지만, 더 유용했던 지점은 예외 케이스를 빨리 넓혀보는 일이었다. 어떤 지역에서 측정소가 멀어질 수 있는지, 과거 데이터가 현재처럼 섞일 여지는 없는지, 화면에서는 그 불확실성을 어디까지 드러내야 하는지를 반복해서 점검했다.
대부분은 기상청과 AirKorea 조합으로 잘 들어왔다. 하지만 검증을 하면서 두 가지가 보였다.
이건 단순한 버그라기보다, 사용자가 앱을 어떻게 믿게 되는가의 문제였다. 데이터가 맞아도 오래된 row가 현재처럼 보이면 신뢰가 깨진다. 측정소가 멀리 있는데 그 사실을 숨기면, 앱은 모르는 것을 아는 척하는 셈이 된다.
그래서 후속 작업은 화려하지 않았다. 과거 시간대 데이터가 현재나 미래 판단처럼 섞이지 않도록 현재 시간 이후만 보게 정리했다. AirKorea 측정소가 멀어지는 경우에는 조용한 신뢰 노트를 둘 수 있게 했다.
이 변화가 크지 않아 보일 수도 있다. 하지만 달릴시간 같은 앱에서는 이런 작은 경계가 중요하다. 점수 하나가 높아도, 사용자가 “이 앱이 지금 내 상황을 제대로 보고 있나?”라고 느끼면 판단은 바로 흔들린다.
결국 이번에 바뀐 것은 날씨 데이터 목록만이 아니었다. 달릴시간이 신뢰를 다루는 방식이었다.
좋은 러닝 시간은 공식 하나로 나오지 않는다. 어떤 데이터를 먼저 보고, 얼마나 최신인지 확인하고, 지역적으로 얼마나 가까운지 의심하고, 부족한 부분은 부족하다고 남기는 일까지 포함된다.
“오늘 달려도 될까?”는 단순한 질문이었다. 그 질문에 단순한 척 답하지 않기 위해 생각보다 많은 신뢰 구조가 필요했다.
2026-05-16
미세먼지, 더위, 습도, 바람, 비를 함께 보는 앱. 기능은 맞았고 제품은 잘 보이지 않았다.
러너가 달리기 전에 조건을 보는 이유는 위험을 피하기 위해서만이 아니다. 같은 노력을 더 좋은 시간에 쓰고 싶기 때문이다. 홈페이지 문구도 날씨 기능보다 그 선택을 먼저 말해야 했다.
러너에게 중요한 것은 달린 뒤의 기록만이 아니라, 달리기 전에 어떤 조건을 선택했는가이기도 했다.
러너는 기록을 위해 훈련한다. 인터벌을 하고, LSD를 하고, Zone 2를 보고, 카본화를 신고, 컨디션을 관리한다. 이 단어들은 러너에게 이미 가치가 있다.
그래서 달릴시간을 설명할 때도 “날씨 데이터를 분석합니다”라고만 말하면 안 된다고 봤다. 러너가 이미 중요하게 여기는 것들 옆에 달릴시간을 놓아야 했다. 그래야 “언제 달릴지”도 훈련과 기록 사이에 있는 중요한 판단으로 읽힐 수 있었다.
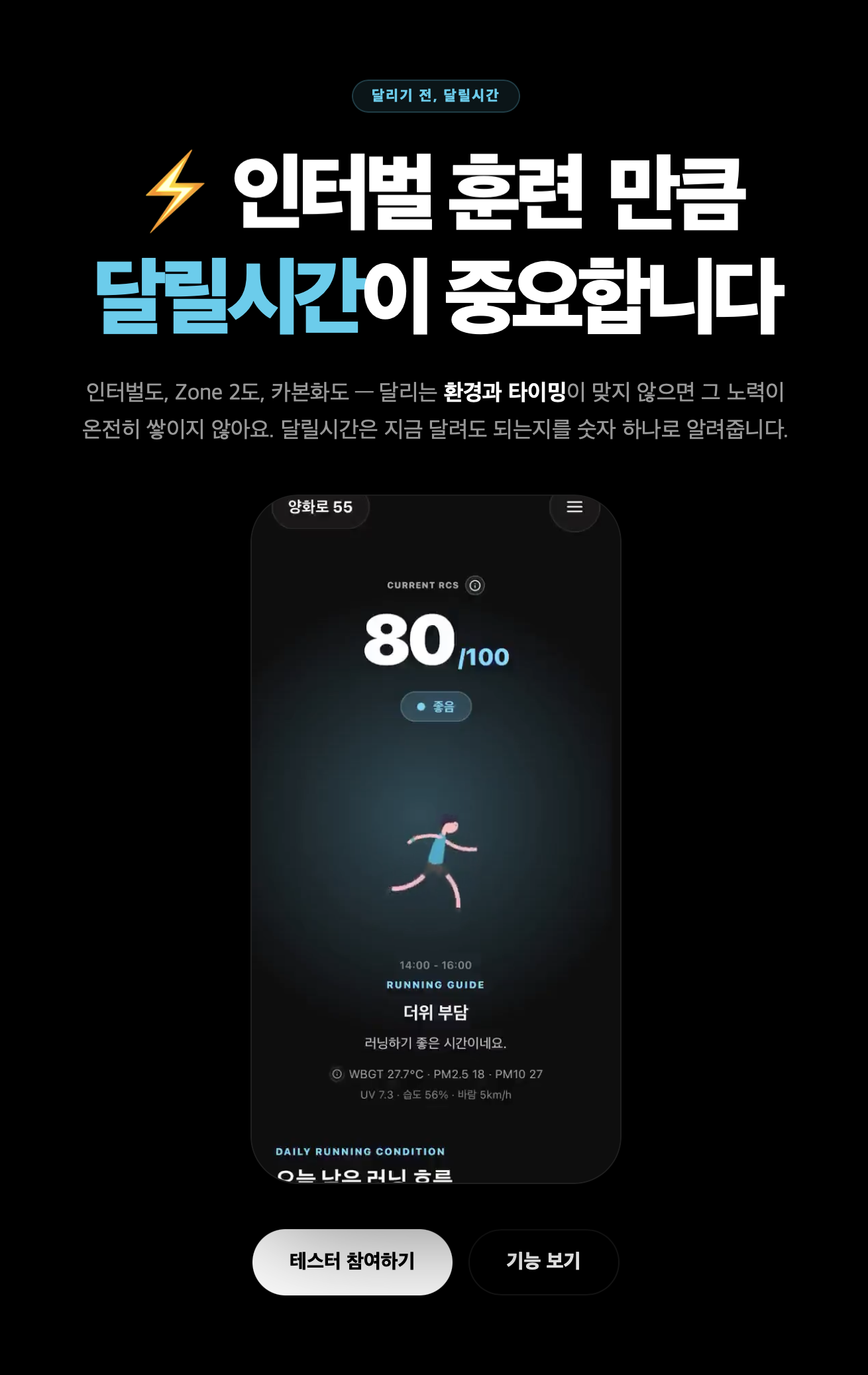
히어로의 키워드는 고정하지 않고 바뀌도록 만들었다. 인터벌 훈련, LSD 훈련, 카본화처럼 러너가 익숙하게 받아들이는 항목이 먼저 나오고, 그 다음에 “달릴시간이 중요합니다”가 이어진다.
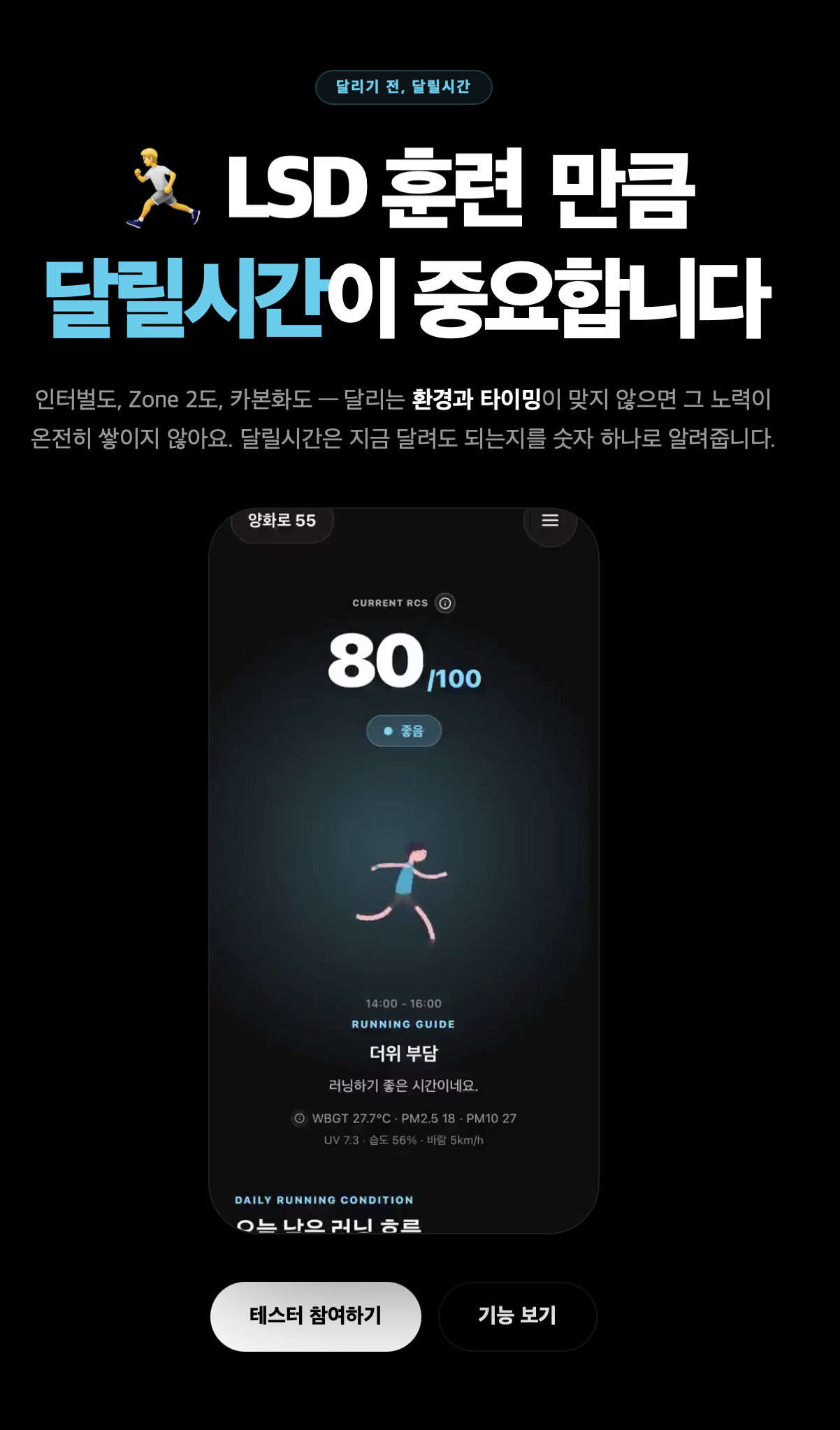
이건 단순한 카피 장치가 아니었다. 기능을 만든 뒤, 그 기능을 러너가 자기 언어로 받아들일 수 있게 번역하는 작업에 가까웠다.
달리고 나면 기록 앱을 본다. 거리, 페이스, 시간, 루트, 심박, 구간 기록이 남는다. 그 데이터는 중요하다. 내가 어떻게 뛰었는지, 다음에는 무엇을 바꿔야 할지 알려준다.
하지만 기록 앱은 대부분 달린 뒤의 이야기를 보여준다. 정작 나가기 전에는 아직 기록이 없다. 그때 필요한 질문은 조금 다르다.
오늘 나가도 괜찮을까?
조금 기다리면 더 나을까?
같은 훈련이라면 어느 시간대가 덜 힘들까?달릴시간이 들어가야 할 자리는 바로 그 앞이었다. 달린 뒤를 평가하는 앱이 아니라, 달리기 전에 오늘의 조건을 먼저 고르는 앱. 이 차이가 보이자 홈페이지와 앱스토어 문구도 달라져야 했다.
기록은 실력만으로 나오지 않는다. 같은 러너, 같은 코스, 같은 훈련이어도 환경이 다르면 몸이 받아들이는 부담이 달라진다. 습도가 높으면 같은 페이스도 더 무겁고, 바람이 강하면 유지하던 속도가 흔들린다. 미세먼지와 더위는 기록뿐 아니라 건강 부담까지 바꾼다.

그래서 달릴시간은 날씨앱도, 기록앱도 아닌 자리를 잡아야 했다. 날씨앱처럼 수치를 많이 보여주는 것이 아니라, 그 수치를 러너가 실행할 수 있는 타이밍으로 바꾸는 앱. 기록앱처럼 달린 뒤를 분석하는 것이 아니라, 달리기 전에 조건을 고르게 돕는 앱.
이렇게 정리하고 나서야 제품의 문장이 조금 선명해졌다.
기록 앱은 달린 뒤를 보여준다.
달릴시간은 달리기 전에 조건을 고르게 돕는다.이 기준은 이후 RCS 프로모션 계산기와 공유 카드에도 이어졌다. RCS를 먼저 설명하지 않고 러너가 자기 기록으로 이해할 장면을 먼저 만들었다. 기록 앱은 달린 뒤를 남긴다. 달릴시간은 그 기록이 시작되기 전의 시간을 고른다.
2026-05-17
제주에는 비가 왔다. 달릴시간은 달리기 괜찮은 조건처럼 보였다.
비 점수를 더 깎으면 될 것 같았다. 하지만 그날만 고치면 다음 오판은 또 처음부터 시작한다. 사용자가 “안 맞아요”라고 말했을 때, 앱이 무슨 근거로 그 판단을 했는지 되돌릴 수 없었기 때문이다.
의견은 짧다. 원인은 길다.
처음 필요한 것은 가벼운 입력이었다. 러너가 앱을 열고 현재 판단을 본 뒤, 그 판단이 지금 체감과 맞는지만 빠르게 알려줄 수 있어야 했다.
그래서 피드백은 세 가지 선택으로 줄였다.
O 맞아요
△ 애매해요
X 안 맞아요메시지는 선택 사항으로 두었다. 베타 테스트에서 중요한 것은 긴 설명을 받는 일이 아니라, 어느 조건에서 판단이 어긋났는지 반복해서 볼 수 있는 구조였다.
하지만 사용자는 가볍게 말하고, 무거운 기억은 앱이 맡아야 했다. “안 맞아요”만 남으면 그때 앱이 무엇을 보고 있었는지 알 수 없었다.
그래서 피드백에는 사용자의 선택만 붙이지 않았다. 앱이 그 순간 보고 있던 조건도 함께 묶었다.

한 행에는 두 개의 판단이 남았다. 특정 시간과 위치에서 앱이 본 세계와 러너가 느낀 세계였다.
구글 시트는 이 단계에서 가장 가벼운 저장소였다. 처음부터 거대한 분석 시스템을 만들기보다, 베타 단계에서 빠르게 행을 보고 문제 유형을 나누는 편이 더 맞았다.
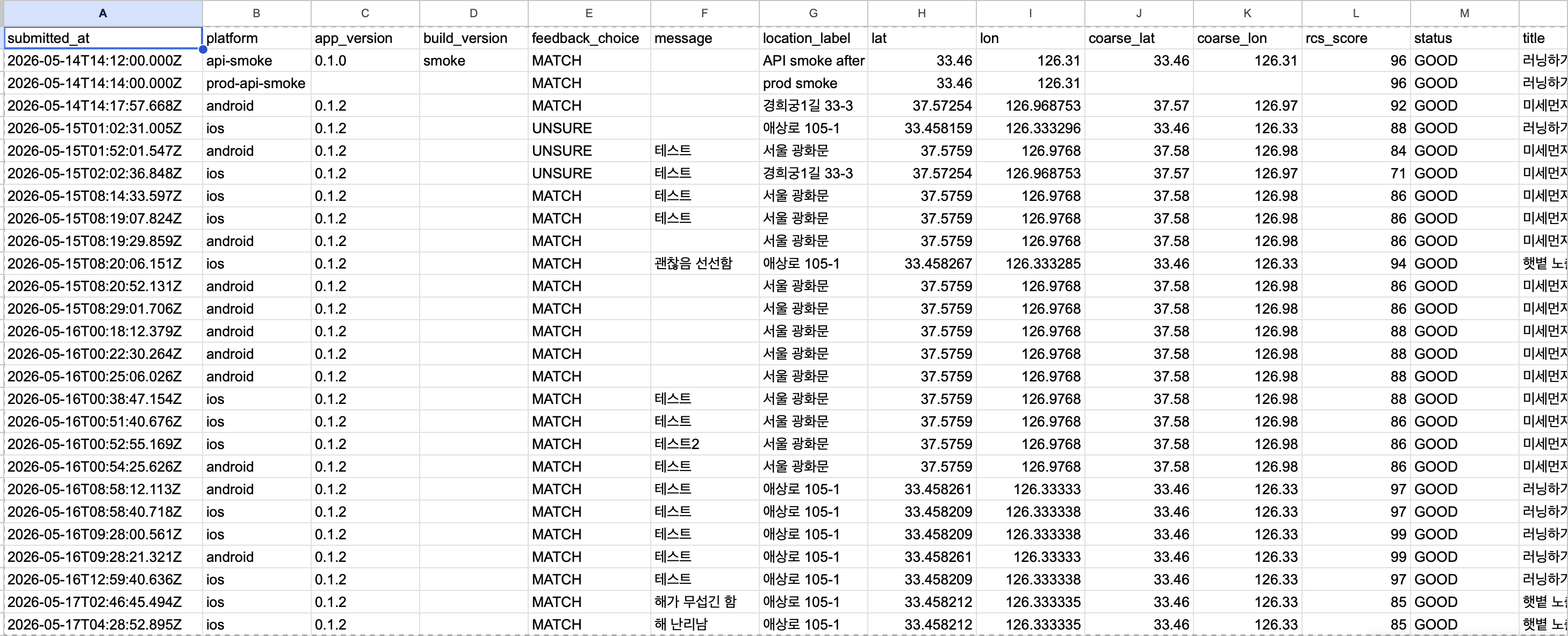
대부분 테스트 데이터였지만, 이 화면은 구조를 확인하기에 충분했다. 피드백은 메모 한 줄이 아니라, 나중에 “왜 그 판단이 맞거나 틀렸다고 느꼈는지” 다시 추적할 수 있는 단서가 되어야 했다.
기술적으로는 홈 화면 안에 피드백 카드를 바로 넣을 수 있었다. 실제로 그 방식이 가장 빨리 확인하기 쉬웠다. 하지만 화면을 보고 나니 문제가 보였다.
달릴시간의 홈은 러너가 “지금 나가도 될까?”를 판단하는 자리다. 그 자리에 피드백 카드가 너무 강하게 들어오면, 앱이 제품이라기보다 내부 QA 도구처럼 보였다.
그래서 피드백 경로를 둘로 나눴다.
설정 → 러닝 판단 피드백수동 경로는 항상 열어두고, 홈의 질문은 자주 보이지 않게 했다. 기본 지연 시간과 쿨다운을 두고, 점수가 낮거나 주의 문구가 있거나 비 관련 문장이 있는 순간처럼 피드백 가치가 높은 상황에서만 더 빨리 묻도록 했다.
피드백을 잘 받으려면 많이 물어보면 된다고 생각하기 쉽다. 하지만 러너가 앱을 여는 이유는 피드백을 주기 위해서가 아니다. 오늘 뛸지, 조금 기다릴지 판단하기 위해서다.
그래서 피드백은 판단을 방해하지 않아야 했다. 현재 조건을 읽고 나서야 묻고, 한 번 닫으면 일정 시간 동안 다시 묻지 않게 했다. 제출한 뒤에도 며칠 동안은 반복해서 묻지 않는다.
이 조정은 작아 보이지만 중요했다. 피드백 기능은 앱을 개선하기 위해 필요하지만, 사용자가 느끼는 제품의 중심을 빼앗으면 안 된다.
이벤트 트래킹도 같은 기준으로 봤다. 베타 단계에서는 실제로 예보가 로드되는지, 결제 흐름이 열리는지, 피드백이 제출되는지 확인해야 한다. 하지만 모든 행동을 넓게 자동 수집하거나 세션을 다시 보는 방식은 달릴시간에 맞지 않았다.
달릴시간은 위치와 컨디션을 다루는 앱이다. 그래서 분석은 더 조심스러워야 했다. 필요한 이벤트만 직접 남기고, 민감한 값은 공개 콘텐츠나 운영 기록에서 드러나지 않도록 구분했다.
PostHog는 그래서 “사용자를 추적하는 도구”라기보다, 베타에서 핵심 흐름이 실제로 지나갔는지 확인하는 제한적인 장치에 가까웠다. 구글 시트는 피드백의 맥락을 보는 도구였고, 이벤트 트래킹은 흐름이 작동하는지를 보는 도구였다.
러닝 조건을 점수로 만드는 일은 한 번에 끝나지 않는다. 실제 러너가 보고, 뛰어보고, 다르게 느끼는 순간이 쌓여야 한다. 그때 중요한 것은 피드백을 많이 받는 일이 아니라, 나중에 다시 고칠 수 있는 형태로 받는 일이다.
달릴시간의 피드백 구조는 그 기준을 세우기 위한 첫 번째 장치였다.
사용자는 가볍게 말한다.
앱은 그 순간의 조건을 함께 남긴다.
그리고 다음 판단은 그 기록을 보고 다시 조정된다.사용자의 X는 실패 표시가 아니었다. 달릴시간이 다음에는 조금 덜 틀리기 위한 좌표였다.
2026-05-19
RCS가 높습니다. 처음 보는 러너에게 남는 것은 의미보다 낯선 약어였다.
Running Condition Score는 기온, WBGT, 미세먼지, 바람, 비를 러닝 관점의 0–100으로 묶는다. 하지만 러너가 궁금한 것은 정의가 아니라 그 점수가 자기 달리기에 어떤 차이를 만들 수 있는지였다.
그래서 프로모션 사이트의 질문을 바꿨다.
RCS가 무엇인지 설명하기 전에,
그날 조건이 달랐다면 내 페이스가 얼마나 달라질 수 있었는지 보여주자.입력 화면은 러너가 이미 알고 있는 값에서 시작했다. 그날의 RCS, 거리, 페이스. 여기에 비교할 조건을 넣으면, 같은 실력일 때 페이스가 어느 정도 달라질 수 있는지 계산해준다.
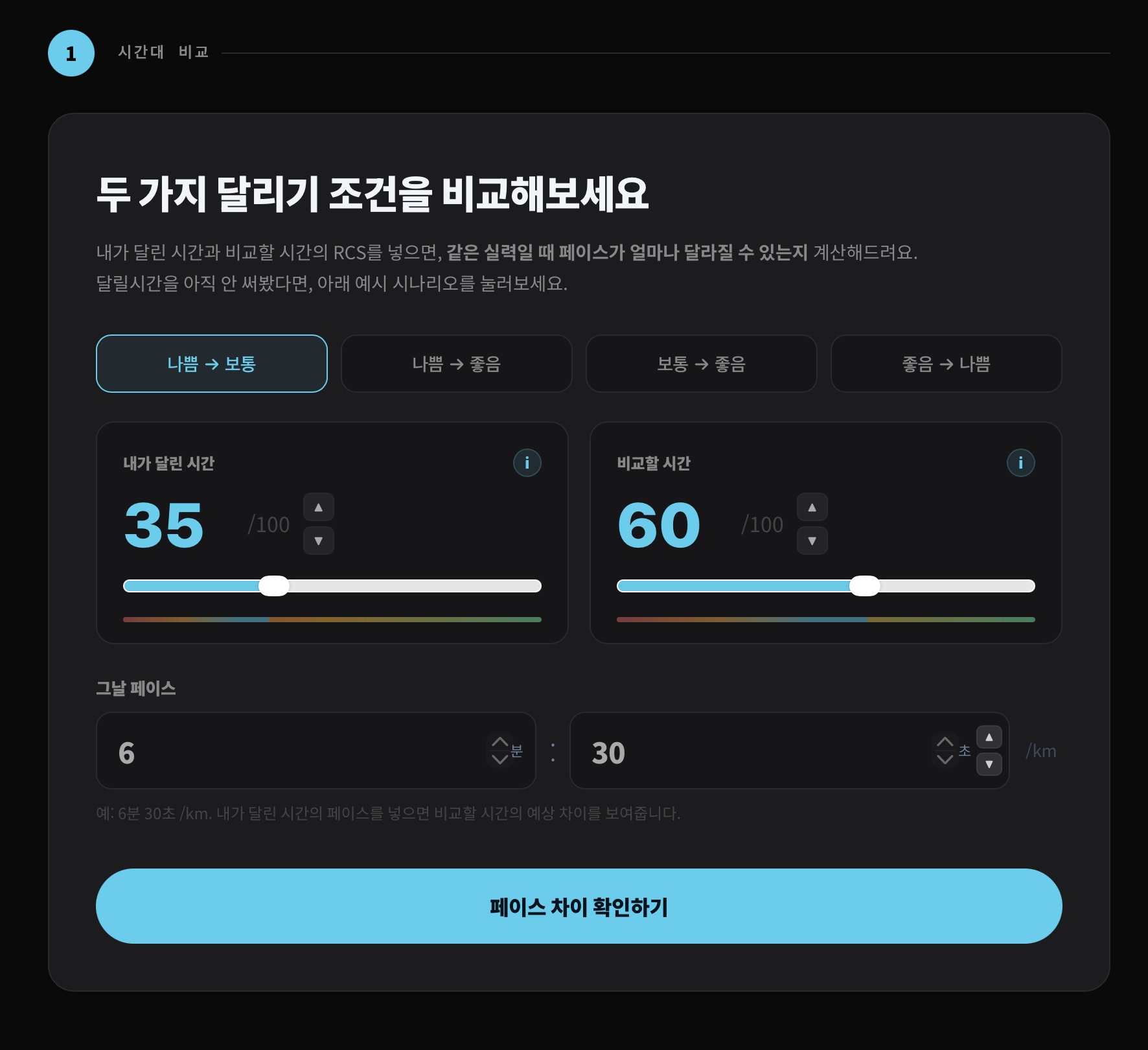
이 구조는 광고 문구보다 직접적이었다. “달릴시간이 좋아요”라고 말하는 대신, 러너가 자기 기록을 넣고 “아, 조건이 다르면 이런 차이로 느껴질 수 있구나”라고 생각하게 만든다.
물론 조심해야 할 선도 있었다. 달릴시간은 기록을 보장하는 앱이 아니다. 좋은 조건이 기록에 영향을 줄 수는 있지만, 개인의 기록은 훈련, 수면, 코스, 컨디션, 보급, 장비, 전략 같은 여러 요소에서 나온다. 그래서 결과는 예측이 아니라 참고 시나리오여야 했다.
기록을 맞히는 계산기가 아니라, 조건 차이를 자기 기록으로 읽어보는 장치에 가깝게 만들자.
RCS 설명은 없애지 않았다. 다만 처음부터 앞세우지는 않았다. 러너가 페이스 차이를 먼저 보고 나면, 그 다음에는 “그럼 RCS가 뭔데?”라는 질문이 자연스럽게 생긴다. 그때 설명이 들어가야 했다.

여기서도 핵심은 숫자의 권위를 키우는 것이 아니었다. RCS는 복잡한 환경 데이터를 러너가 읽을 수 있는 하나의 판단 단위로 낮추는 장치다. 기온이 같아도 습도와 바람, 햇볕이 다르면 몸이 받는 부담은 달라진다. 미세먼지가 높으면 페이스보다 노출 시간을 먼저 봐야 할 수도 있다.
이런 차이를 매번 직접 해석하라고 하면 앱의 의미가 줄어든다. 달릴시간은 그 해석을 러너의 질문으로 바꾸려고 했다.
오늘 달려도 될까?
조금 기다리면 더 나을까?
이 기록은 조건의 영향을 얼마나 받았을까?프로모션 사이트를 만들면서 가장 경계한 것은 과장이다. “좋은 조건이면 기록이 오른다”는 메시지는 매력적이지만, 너무 쉽게 오해될 수 있다.
그래서 계산 결과는 하나의 확정값이 아니라 범위와 시나리오에 가깝게 다뤘다. “이 기록은 원래 이랬어야 한다”가 아니라, “그날 조건이 달랐다면 이런 차이를 참고해볼 수 있다”는 말이다.
선을 낮추자 제품의 자리가 더 선명해졌다. 달릴시간은 기록을 예언하지 않는다. 러너가 이미 가진 기록을 그날의 조건과 함께 다시 읽게 한다. RCS는 설명으로 이해된 게 아니라, 내 페이스를 넣어본 뒤 비로소 의미가 생겼다.
참고: Ely et al. (2007), El Helou et al. (2012), Marr & Ely (2010), Cusick et al. (2023), Nikolaidis et al. (2019), Weiss et al. (2024), WHO Air Quality Guidelines, NWS WBGT guidance.
2026-05-19
처음 결과 화면은 정확했다. 입력값, 비교 조건, 예상 범위를 차분히 보여줬다. 그리고 아무도 저장하고 싶지 않을 것처럼 보였다.
계산이 끝났는데 장면이 남지 않았다. RCS가 러너 사이의 대화가 되려면 결과표보다 자기 기록처럼 간직할 카드가 필요했다.
숫자를 설명하는 화면이 아니라, 러너가 자기 기록처럼 남길 수 있는 이미지가 필요했다.
결과 카드의 중심에는 스톱워치를 두었다. 페이스를 말하는 페이지라면, 숫자보다 먼저 기록의 상징이 보여야 했다. 그 아래에는 긴 설명 대신 한 문장을 남겼다.
더 좋은 조건에서 달리면 약 20초 빨라질 수 있어요.물론 이 문장은 기록을 보장하는 말이 아니다. 입력한 조건을 바탕으로, 더 나은 RCS 시나리오에서는 어느 정도 차이를 참고해볼 수 있는지 보여주는 말이다. 그래서 카드 안에서도 “조건”과 “가능성”의 뉘앙스를 유지해야 했다.

카드 하단에는 “달리기 전, 달릴시간에서.”라는 짧은 문장과 QR을 붙였다. 결과 이미지만 돌면 제품과의 연결이 끊길 수 있기 때문이다. 러너가 이미지를 보고 “이게 뭔데?”라고 물었을 때, 바로 다시 달릴시간으로 이어지는 길이 필요했다.
이 작업을 하면서 가장 크게 바뀐 생각은 이것이었다. 필요한 기능을 만들고 내용을 채워 넣는 것만으로는 충분하지 않다. 러너가 이해하고 공감할 수 있는 말과 장면으로 다시 번역해야 한다.
RCS는 기술적으로는 점수다. 하지만 러너에게는 “오늘 내 페이스가 왜 이렇게 느껴졌는지”, “조금 기다렸다면 달라졌을지”를 생각하게 만드는 단서가 되어야 했다. 그래서 결과 카드는 기능의 출력물이 아니라, 러너가 자기 기록을 다시 이야기할 수 있는 작은 소재에 가까워졌다.
공유 버튼을 붙인 이유도 여기에 있었다. 달릴시간이 먼저 제품을 설명하는 것보다, 러너가 자기 기록을 두고 다른 러너에게 말을 거는 편이 더 자연스럽다.
그날 조건이 더 좋았다면,
내 페이스도 달라졌을까?이 질문이 공유 카드 안에 남아 있으면, RCS는 낯선 점수가 아니라 대화의 출발점이 된다.
카드를 더 강하게 만들고 싶은 유혹도 있었다. “기록이 빨라진다”는 문장은 눈에 잘 띈다. 하지만 달릴시간이 지켜야 할 선은 그 반대쪽에 있었다.
기록을 약속하지 않기. 개인의 성과를 단정하지 않기. 대신 환경 조건이 달리기 체감과 실행 난이도에 영향을 줄 수 있다는 사실을, 러너가 자기 기록으로 다시 읽어볼 수 있게 만들기.
이 카드는 성과를 약속하는 광고가 아니라 조건을 다시 보게 하는 작은 기록이어야 했다. 계산기가 이해를 만들었다면, 카드는 그 이해가 러너의 사진첩과 대화 속에 남는 방식이었다.
2026-06-19
홈페이지에 테스터 신청 버튼을 붙였다. 이메일이 들어왔다. 아직 아무도 앱을 설치한 것은 아니었다.
신청과 사용 사이에는 플랫폼별 계정 등록, 초대, 설치 안내가 남아 있었다. 설치 뒤에는 앱의 판단이 러너의 체감과 맞았는지 돌아오는 길도 필요했다.
신청 버튼은 모집의 끝이 아니라 운영 루프의 입구였다.
iOS와 Android는 테스트 방식이 다르다. iOS는 TestFlight 초대가 필요하고, Android는 Google Play 비공개 테스트 계정 등록이 필요하다. 특히 Android는 사용자가 실제 Play Store에 로그인한 Google 계정으로 등록되어야 설치 권한 문제가 줄어든다.
그래서 신청 폼에서 먼저 테스트할 기기를 고르게 했다. 선택한 플랫폼에 맞는 계정을 따로 받고, 설치 안내를 보낼 연락처도 구분했다.
폼 상단에는 “먼저 써보실래요?”라는 초대 문장과 함께 계정을 받는 이유와 사용 목적을 적었다. 러너에게는 신청 화면이지만, 운영자에게는 플랫폼별 초대와 설치 안내의 출발점이었다.
신청이 Google Sheet에만 쌓이면 운영자가 놓치기 쉽다. 그래서 신청이 들어오면 Discord의 tester-signups 채널로 바로 알림이 오게 했다.
알림에는 닉네임, 계정, 유입 경로, 등록 시간이 함께 들어온다. 운영자는 이 정보를 보고 TestFlight나 Google Play 테스터 목록에 추가하고, 안내 메시지를 보낼 수 있다.
거창한 자동화가 필요했던 것은 아니다. 테스트 초반에는 신청자 한 명을 놓치는 일도 크다. 누가 어떤 플랫폼으로 신청했고, 다음에 어떤 초대와 안내가 필요한지 바로 확인할 수 있으면 됐다.
신청 → 플랫폼별 초대 → 설치 안내 → 사용 → 피드백어느 한 단계에서 멈추면 신청자 수가 늘어도 실제 사용자는 늘지 않는다.
설치가 끝났다고 테스트가 끝나는 것도 아니었다. 달릴시간은 러닝 조건을 판단하는 앱이므로, 사용자가 그 판단을 어떻게 느꼈는지 다시 돌아와야 했다. “좋아요”나 “별로예요”만 받지 않고, 그 순간 앱이 보고 있던 조건을 함께 남긴 이유다.
앱에서 남긴 피드백은 feedback-manager 채널로 들어오게 했다. 플랫폼, 버전, 위치 라벨, 상태, RCS 점수, 사용자 평가, 메시지를 함께 확인할 수 있다.
예를 들어 앱은 GOOD이라고 판단했지만 사용자는 “애매해요”라고 느낄 수 있다. 이때 앱이 틀렸다고 바로 단정할 수는 없다. 어떤 조건에서 사용자의 체감과 앱의 판단이 갈라졌는지 다시 봐야 한다.
이 피드백이 쌓이면 RCS를 조정할 때도 더 구체적인 질문을 할 수 있다.
이렇게 돌아온 피드백은 앱의 판단과 러너의 체감 사이를 다시 맞춰보는 재료가 됐다.
베타 테스트는 앱을 열어두는 일만으로 굴러가지 않았다. 사용자가 들어오고, 설치하고, 써보고, 판단을 돌려줄 수 있어야 했다.
물론 아직 완전한 운영 자동화는 아니다. 초대와 안내에는 여전히 사람이 개입한다. 하지만 신청, 초대, 설치, 피드백이 한 흐름으로 연결되기 시작했다는 점이 중요했다.
신청 한 건이 플랫폼별 초대와 설치로 이어지고, 사용 뒤의 피드백이 다시 제품 판단으로 돌아올 때 테스트가 한 바퀴 돈다. 버튼은 러너를 모았다. 운영 루프는 그 러너가 실제로 앱을 쓰고 다음 판단을 바꾸게 했다.
2026-06-22
“일출 일몰시간도 있었으면.”
테스터가 남긴 문장은 이게 전부였다. 앱의 점수는 맞았다. 그런데 19시가 햇볕이 줄어드는 때인지, 곧 어두워질 때인지는 따로 찾아봐야 했다.

요청대로 일출·일몰 시각만 한 줄 추가할 수도 있었다. 하지만 이 피드백이 드러낸 문제는 정보 하나가 빠졌다는 것보다 컸다. 달릴시간은 시간대별 점수를 보여주고 있었지만, 러너가 그 시간을 어떻게 느끼는지는 충분히 설명하지 못하고 있었다.
달릴시간은 온도, 습도, 비, 바람, 미세먼지 같은 조건을 묶어 “지금 뛰어도 괜찮은가”를 판단한다. 그래서 처음에는 일출·일몰을 날씨 옆에 붙는 부가 정보처럼 생각하기 쉬웠다.
하지만 러너가 시간을 고를 때는 해가 떠 있는지, 곧 어두워지는지, 시야가 얼마나 남아 있는지도 함께 본다. 특히 여름에는 같은 기온이라도 햇볕이 남아 있는 시간과 해가 넘어간 뒤의 체감이 다르다.
낮에는 기온이 조금 내려가도 햇볕 부담이 남아 있다. 반대로 일몰 직전이나 직후에는 더위 부담이 줄고, 아직 완전히 어둡지는 않아 비교적 부담 없이 나갈 수 있는 시간이 생긴다. 러너가 그 시간을 따로 확인해야 한다면, 앱이 이미 보여준 점수만으로는 충분하지 않은 셈이었다.
이전 화면도 시간대별 추천은 보여줬다. 18시, 19시, 20시처럼 남은 시간의 점수와 상태를 비교할 수 있었다.

문제는 그 시간대가 러너에게 어떤 시간인지 바로 읽히지 않았다는 점이다. 19시가 해가 넘어가는 시간이라면 단순히 18시 다음 카드가 아니다. 같은 점수라도 “지금 나가면 햇볕이 덜하겠다”거나 “조금 늦으면 시야를 더 신경 써야겠다”는 판단이 달라진다.
이 피드백은 러너가 시간표를 읽는 방식을 앱 안으로 가져오라는 신호에 가까웠다.
그렇다고 일몰 전후라고 무조건 점수를 올리면 안 된다. 비가 오거나, 미세먼지가 나쁘거나, 열 부담이 큰 날에는 해가 진다는 이유만으로 좋은 조건이 되지 않는다. 안전 리스크를 흐리면 달릴시간의 기본 판단이 약해진다.
그래서 점수 자체를 크게 바꾸지 않았다. 일출·일몰 시간을 데이터로 가져오고, 추천 시간 안에서 그 맥락을 설명하게 했다. 비슷하게 좋은 후보가 있을 때는 일몰에 가까운 시간을 더 자연스럽게 읽을 수 있게 하고, 화면에는 일몰, 일몰 후 같은 라벨을 붙였다.
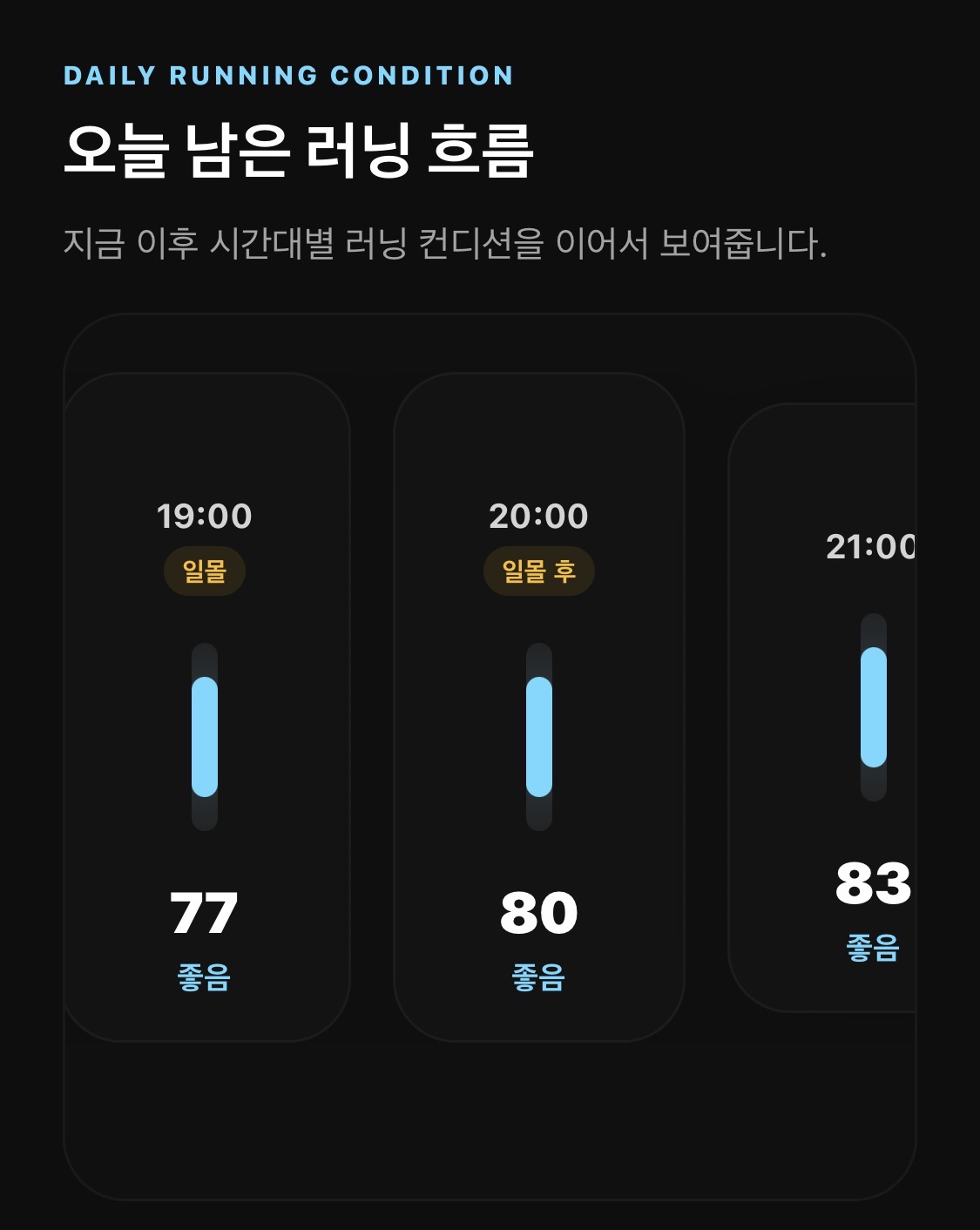
이제 19시는 숫자만 적힌 시간 카드가 아니다. 러너에게는 햇볕 부담이 줄어드는 시간이고, 20시는 시야 확보를 조금 더 신경 써야 하는 시간으로 읽힌다. 앱이 같은 점수를 보여주더라도, 사용자는 그 시간의 실제 느낌을 더 잘 상상할 수 있다.
바뀐 것은 기능 수보다 추천 시간을 읽는 방식이었다. 달릴시간이 보던 조건이 날씨 데이터에서 러너가 실제로 시간을 고르는 맥락까지 넓어졌다.
테스터 모집을 열면서 만든 피드백 흐름은 처음에는 운영 장치처럼 보였다. 누가 앱을 써봤는지, 판단이 맞았는지, 어떤 메시지를 남겼는지 놓치지 않기 위한 구조였다. 그런데 실제 피드백이 들어오자 그 흐름은 제품의 가치를 높이는 통로가 됐다.
러너는 “점수가 맞다/틀리다”만 말하지 않았다. 어떤 정보가 있어야 나갈 시간을 고를 수 있는지도 알려줬다. 그 말을 반영하자 19시는 점수 하나가 아니라, 햇볕과 시야까지 함께 판단할 수 있는 시간이 됐다.
달릴시간이 답해야 하는 것은 가장 높은 점수의 시각만이 아니었다. 19시가 러너에게 어떤 빛과 시야의 시간인지까지 보여줘야 했다. 숫자는 그대로였지만, 추천 시간은 비로소 장면이 됐다.
브랜드 / 홈페이지
WHY
쌓아온 활동을, 처음 보는 사람도 위밋업의 관점으로 읽게 만들 수 있을까? 기존 홈페이지에는 연구, 교육, 이벤트, 지원 활동이 있었지만, 각각의 활동이 어떤 생각 아래 연결되는지는 빠르게 보이지 않았습니다.
HOW
WMS는 현장 경험, 위밋업은 확장 구조로 나눴습니다. 그 기준으로 Woman. The Player.와 Every One. The Player.의 관계를 세우고, 홈페이지 첫 화면과 운영 구조로 옮겼습니다.
WHAT
Every One. The Player.를 설명하는 브랜드형 홈페이지로 다시 설계했습니다. 히어로 카피, 트로피 심볼, 한·영 운영 구조, 파트너/프로그램 섹션을 하나의 브랜드 논리로 연결했습니다.
2026-05-12
기존 홈페이지에는 연구, 교육, 이벤트, 기부, 공지와 현장 이미지가 모두 있었다. 활동은 많았고, WMS와 위밋업이 왜 함께 있는지는 보이지 않았다.
리뉴얼의 첫 일은 화면을 꾸미는 것이 아니라 두 이름의 역할을 나누는 일이었다. 공공기관, 파트너, 후원자, 새 방문자가 WMS의 경험과 위밋업의 구조를 한 번에 구분해 읽어야 했다.

기존 홈페이지는 활동과 조직 정보를 보여주고 있었지만, 위밋업과 WMS가 각각 어떤 역할을 맡는지 한 번에 읽히지는 않았다.
이 프로젝트에서 가장 먼저 잡아야 했던 문장은 이쪽에 가까웠다.
WMS는 현장의 경험을 보여주고, 위밋업은 그 경험이 더 넓게 이어질 구조를 설명한다.
WMS는 여성이 실제로 스포츠를 삶 안으로 들여오는 경험을 만든다. 클래스, 프로그램, 커뮤니티, 반복되는 참여 경험이 있고, 그 안에서 누군가는 처음으로 운동을 시작하고, 누군가는 자신에게 맞는 스포츠 루틴을 갖게 된다. 그래서 WMS는 직접적인 플레이어 경험을 보여주는 축에 가깝다.
반대로 위밋업은 조금 더 넓은 층에 있다. 특정 프로그램 하나를 운영하는 브랜드라기보다, 더 많은 사람이 스포츠에서 소외되지 않고 각자의 방식으로 플레이어가 될 수 있는 조건을 만든다. 연구하고, 교육하고, 행사를 만들고, 파트너와 협력하고, 필요한 자원을 연결한다.
이렇게 나누고 나니 홈페이지의 역할도 달라졌다. 활동 목록을 진열하는 데서 멈추지 않고, 각각의 활동이 어떤 관점 아래에 놓이는지 보여줘야 했다.
그 중심에 PLAYER라는 단어가 있었다. 여기서 PLAYER는 경기에 뛰는 사람이나 운동을 잘하는 사람만을 뜻하지 않는다.
위밋업과 WMS가 말하는 플레이어는, 스포츠를 자기 삶 안으로 각자의 방식으로 들여오는 사람에 가깝다. 직접 뛰는 사람일 수도 있고, 응원하는 사람일 수도 있고, 운동을 통해 일상을 회복하는 사람일 수도 있다. 중요한 것은 스포츠가 누군가의 삶에 들어와 긍정적 변화를 만들 수 있다는 관점이다.
그래서 WMS와 위밋업의 카피도 같은 단어를 공유하지만, 서로 다른 역할을 맡아야 했다.
Woman. The Player.
Every One. The Player.Woman. The Player.는 WMS가 만드는 집중된 경험이다. 여성들이 실제로 플레이어가 되는 경험을 구체적으로 보여준다.
Every One. The Player.는 위밋업이 더 넓게 설명해야 할 관점이다. 모두를 하나의 덩어리로 부르는 대신, 한 사람 한 사람을 플레이어가 될 수 있는 존재로 다시 부른다. 그래서 Everyone이 아니라 Every One으로 나누는 쪽이 더 맞았다.
이 차이는 단순한 카피 수정이 아니라, 두 브랜드가 같은 세계관 안에서 서로 다른 위치를 갖게 되는 순간이었다.
프로젝트를 둘러싼 맥락에는 더 큰 대외 노출 기회도 있었다. 하지만 그 기회를 홈페이지의 중심에 놓는 것은 조심스러웠다. 중요한 배경은 될 수 있어도, 위밋업이 스스로 말해야 할 핵심 메시지는 아니었기 때문이다.
오히려 홈페이지의 중심에는 위밋업 자신의 문장이 있어야 했다. 더 많은 사람이 스포츠를 자기 삶 안으로 들여올 수 있어야 한다는 관점. 그리고 그 관점이 단순한 선언이 아니라 실제 활동, 파트너십, 교육, 연구, 이벤트, 후원 구조로 이어지고 있다는 근거.
그래서 방향은 점점 “스포츠 에너지”보다 “근거가 보이는 조직” 쪽으로 이동했다. 힘 있는 첫인상은 필요했지만, 그것이 이벤트 포스터처럼 보이면 안 됐다. 위밋업은 하나의 활동을 홍보하는 곳이 아니라, 활동들이 쌓여 사회적 조건을 함께 만들어가는 조직처럼 읽혀야 했다.

새 방향에서는 Every One. The Player.를 첫 문장으로 두고, 실제 현장의 이미지들을 트로피 형태 안에 모아 조직의 관점과 근거를 함께 보여주려 했다.
첫 문장이 바뀌면 사이트의 구조도 달라진다. Every One. The Player.가 앞에 온다면, 그 아래에는 왜 이 문장이 가능한지 보여주는 근거가 필요하다.
그래서 활동은 단순 나열이 아니라 역할을 갖는다.
이렇게 보면 홈페이지 리뉴얼은 화면을 바꾸는 일이기 전에, 조직의 말을 다시 배열하는 일이었다. 무엇을 앞에 두고, 무엇을 배경으로 내리고, 어떤 단어를 공유하고, 어떤 증거를 붙일지 정하는 일.
여기서 남은 결론은 분명했다. 위밋업은 WMS와 같은 세계관을 공유하지만 같은 일을 하는 조직은 아니었다. WMS가 플레이어 경험을 보여준다면, 위밋업은 더 많은 사람이 플레이어가 될 수 있도록 연구·교육·협력의 구조를 설명해야 했다.
WMS는 PLAYER가 되는 장면을 보여줬다. 위밋업은 그 장면이 더 많은 사람에게 이어질 연구·교육·협력의 구조를 설명했다. 역할을 나누자 두 이름은 경쟁하지 않고 서로의 근거가 됐다. 다음 문제는 이 관계를 첫 화면의 한 이미지로 보여주는 일이었다.
2026-05-13
강한 스포츠 포스터, 활동을 빼곡히 놓은 proof grid, 현장 이미지를 품은 트로피를 나란히 놓았다.
WMS가 플레이어 경험을 보여주고 위밋업이 연구·교육·협력의 구조를 설명한다는 문장은 이미 있었다. 문제는 긴 설명을 읽기 전 첫 화면에서 그 관계가 보이느냐였다.
AI 비주얼은 완성본이 아니라 첫인상을 빠르게 비교하는 재료로 썼다. 방향이 늘어날수록 분명해진 것은 멋진 이미지보다 위밋업의 관점이 먼저 읽혀야 한다는 점이었다.
이 질문의 답이 바로 트로피는 아니었다. 오히려 몇 가지 그럴듯한 방향을 지나면서, 무엇이 맞지 않는지를 먼저 확인해야 했다.
처음에는 강한 타이포그래피와 스포츠 이미지가 자연스럽게 떠올랐다. Every One. The Player.라는 문장은 크고 단단하게 놓기 좋았고, 스포츠 이미지를 크게 쓰면 첫인상도 빠르게 생겼다.

초기 방향 중 하나. 스포츠 문화 브랜드처럼 강한 인상을 만들 수 있었지만, 위밋업이 가진 연구·교육·파트너십·지원 구조까지 설명하기에는 다소 포스터에 가까웠다.
이 방향은 에너지가 있었다. 기존 홈페이지가 가진 정적인 인상과 비교하면 훨씬 선명했고, 스포츠라는 범주도 바로 느껴졌다.
하지만 위밋업의 첫 화면이 단지 강한 스포츠 포스터처럼 보이는 것은 위험했다. 위밋업은 하나의 이벤트를 홍보하는 곳이 아니라, 더 많은 사람이 스포츠에 접근할 수 있는 조건을 함께 만들어가는 조직이었다. 연구, 교육, 현장 프로그램, 파트너십, 후원 구조가 함께 읽혀야 했다.
그래서 이 방향은 일부 감각을 남기되, 최종 첫인상으로는 충분하지 않다고 봤다.
다음으로 중요하게 본 것은 “근거”였다. 위밋업이 무엇을 말하려면, 그 말은 활동의 근거와 함께 보여야 했다. 그래서 파트너, 프로그램, 활동 영역, 현장의 문장을 카드처럼 배치하는 proof grid 방향도 검토했다.

근거 그리드 방향은 활동 구조와 신뢰 요소를 보여주기에 좋았다. 다만 첫 화면의 상징이라기보다는, 홈페이지 아래에서 관점을 받쳐주는 구조에 더 가까웠다.
이 방향은 논리적으로는 꽤 맞았다. 연구, 교육, 코칭, 프로그램, WMS, 파트너, 참여자의 문장을 하나의 표면에 놓으면 위밋업이 단순 활동 단체가 아니라 구조를 가진 조직처럼 보일 수 있었다.
다만 첫인상으로는 너무 설명적이었다. 들어오자마자 여러 카드를 읽게 만드는 방식은 신뢰를 쌓는 데는 좋지만, 하나의 상징으로 남기는 힘은 약했다.
정리하면 이랬다.
그래서 필요한 것은 두 가지를 동시에 잡는 장치였다. 스포츠와 연결되면서도, 실제 활동의 증거를 담을 수 있고, 조직의 규모감도 느껴지는 형태.
그 지점에서 트로피가 남았다. 트로피는 스포츠와 성취를 바로 떠올리게 한다. 하지만 이번 방향에서 트로피는 승자를 위한 상징으로 쓰고 싶지 않았다. 위밋업이 말하려는 것은 엘리트의 승리가 아니라, 더 많은 사람이 각자의 방식으로 플레이어가 될 수 있는 환경이었기 때문이다.
그래서 트로피는 “누가 이겼는가”의 상징이 아니라, 위밋업과 WMS가 만들어온 현장의 증거를 담는 그릇으로 바뀌었다.

최종 방향에서는 트로피 형태 안에 실제 활동 이미지를 담았다. 하나의 스포츠 상징 안에 위밋업이 만든 현장과 증거를 모으는 방식이다.
이 방식이 좋았던 이유는 세 가지였다.
트로피 안에 들어간 이미지는 장식이 아니다. 그것은 위밋업이 보여주려는 세계가 실제 현장과 연결되어 있다는 표시다. Every One. The Player.라는 문장이 추상적인 선언으로만 보이지 않으려면, 그 아래에는 “이미 이런 장면들이 있다”는 근거가 필요했다.
첫 화면의 상징이 정해졌다고 끝나는 것은 아니었다. 오히려 그다음이 중요했다. 트로피가 증거를 담는 상징이라면, 그 아래의 페이지 구조도 같은 방향으로 이어져야 했다.
파트너 로고는 신뢰의 근거가 되고, Work 영역은 연구·교육·스포츠 이벤트라는 활동 구조를 보여준다. About은 조직의 이유를 설명하고, Donate는 그 조건을 함께 만들 수 있는 참여 경로가 된다.

최종 홈 방향은 상징에서 끝나지 않고, 파트너·활동 구조·조직 설명으로 이어지도록 설계됐다.
이때 아임웹이라는 제작 환경도 판단에 영향을 줬다. 완전히 커스텀한 인터랙션을 끝없이 만드는 것보다, 클라이언트가 운영할 수 있는 구조가 필요했다. 그래서 한글/영문 코드 세트, 재사용 가능한 페이지 타이틀, 공통 푸터, CMS로 처리할 영역을 나눠가는 방식이 중요해졌다.
결국 2회차에서 남는 판단은 단순하다.
트로피는 예쁜 장식이 아니라, Every One. The Player.라는 관점을 첫 화면에서 믿을 수 있게 만드는 방식이었다. 포스터처럼 보이기보다 조직처럼 보이고, 설명만 늘어놓기보다 하나의 상징으로 기억되며, 그 안에 실제 현장의 근거를 담는 방향.
포스터의 에너지와 proof grid의 근거를 한 화면에 모두 얹을 수는 없었다. 트로피는 둘 사이에서 스포츠의 상징을 남기고 실제 활동을 안에 담았다. 위밋업의 문장은 그렇게 이미지가 되었고, 이미지는 다시 운영 가능한 웹사이트 구조가 됐다.
퍼블리싱 시스템
WHY
작업 중간의 선택을, 읽을 만한 이야기로 남길 수 있을까? 결과물만 보여주면 중요한 질문과 판단이 사라졌습니다. 그 과정을 기록하고 다시 엮는 방법이 필요했습니다.
HOW
프로젝트가 움직이는 순간의 질문과 전환점을 짧게 남겼습니다. 그 기록을 그대로 공개하지 않고, 다시 검토해 처음 보는 사람도 읽을 수 있는 이야기로 정리합니다.
WHAT
내 홈페이지 안에서 결과물 뒤의 선택까지 읽을 수 있게 만들고 있습니다. 짧은 작업 메모를 고르고, 글의 방향을 잡고, /projects 화면에서 다시 읽어보며 다듬습니다.
2026-05-11
“할 수 있을까?”라고 적어둔 질문이 어느 날 실제 프로젝트 폴더가 되어 있었다.
자기소개와 완료한 프로젝트를 정리하면 홈페이지 한 장은 빨리 만들 수 있다. 하지만 ami0iam에 남기고 싶은 장면은 완성된 이력보다 그 앞에 있었다. 질문을 붙잡고 자료를 모으고, 비교하고, 버리고, 결국 실제로 만드는 순간이었다.
질문은 이력서에 남지 않는다. 대신 내가 다음에 무엇을 만들지 결정한다.

질문 하나가 계속 머릿속에 남아 작업의 출발점이 되는 순간. GIF via
GIPHY / SAP
.
이 사이트의 출발점은 그 장면을 어떻게 남길 것인가에 가까웠다.
요즘의 일은 하나의 이름표 안에 오래 머무르지 않는다. 어떤 날은 제품을 만들고, 어떤 날은 브랜드를 정리하고, 어떤 날은 강의나 컨설팅을 준비하고, 또 어떤 날은 달리기 앱의 판단 모델을 다시 본다. 겉으로 보면 서로 다른 일처럼 보이지만, 안쪽에서는 비슷한 흐름이 반복된다.
먼저 질문이 생긴다. 그 질문을 붙잡고 자료를 모으고, 비교하고, 버리고, 다시 만든다. 그러다 어느 순간 질문은 작업이 되고, 작업은 프로젝트가 된다.
ami0iam이라는 이름도 그 사이에 있다.
am I
→ I am“나는 이걸 할 수 있을까?”라는 질문이 “나는 지금 이걸 하고 있다”는 상태로 바뀌는 과정. 그 과정이야말로 이 홈페이지가 보여주고 싶은 정체성에 가까웠다.
문제는 일반적인 포트폴리오 형식이 이 과정을 잘 담지 못한다는 점이었다. 결과물은 올릴 수 있다. 링크도 붙일 수 있고, 간단한 설명도 쓸 수 있다. 하지만 그 프로젝트가 왜 시작됐는지, 어떤 판단을 거쳐 지금의 형태가 됐는지, 무엇을 버렸고 무엇을 남겼는지는 쉽게 사라진다.
작업 기록은 남아 있었다. 커밋도 있고, 메모도 있고, 대화도 있었다. 그런데 그 기록들은 대부분 안쪽 사람 기준으로 남는다. 나중에 다시 보면 “무엇이 바뀌었는가”는 알 수 있어도, “왜 그게 중요한 변화였는가”는 바로 읽히지 않았다.
그래서 내 홈페이지를 단순한 자기소개 페이지로 끝내는 대신, 프로젝트가 진행되는 동안 생긴 판단의 흐름을 읽을 수 있는 자리로 바꿔보고 싶었다.
이것이 ami0iam의 첫 번째 문제의식이었다.
처음부터 거창한 콘텐츠 시스템을 만들려고 한 것은 아니었다. 다만 프로젝트를 할 때마다 비슷한 아쉬움이 남았다. 중요한 판단은 대화 중에 지나가고, 비교했던 선택지는 파일명만 남고, 막상 나중에 글로 쓰려고 하면 왜 그 순간이 중요했는지 다시 복원해야 했다.
그러면 글은 쉽게 결과 보고처럼 바뀐다. “무엇을 만들었다”는 말은 남지만, 그 일을 왜 하게 됐고 어떻게 풀어보려 했는지는 얇아진다.

결과보다 “이게 어디로 이어질까”가 더 중요해지는 순간. GIF via
GIPHY / TrueReal
.
ami0iam은 이 문제를 내 홈페이지 안에서 먼저 풀어보려는 시도다. 홈은 내가 누구인지 빠르게 보여주는 입구로 두고, 실제로는 프로젝트별로 판단이 바뀐 순간과 작업의 흐름을 쌓아가는 구조를 만들고 있다.
이후에 이것은 커밋 기반 콘텐츠 실험으로 이어졌고, 다시 짧은 판단 메모를 남기는 방식으로 바뀌었다. 하지만 그보다 앞에 있던 질문은 단순했다.
무엇을 했는가보다, 어떤 질문이 나를 그 일로 데려갔는가.
ami0iam은 그 질문에 답하려다 홈페이지가 되었고, 질문을 잃지 않으려다 퍼블리싱 실험이 되었다.
2026-05-11
커밋 범위, 산출물, 제목, 요약, 섹션까지 모두 뽑혔다. 글의 모양은 생겼다. 읽고 싶은 장면은 생기지 않았다.
첫 실험은 커밋과 관련 산출물을 묶어 프로젝트가 움직인 과정을 복원하는 일이었다. 기록이 이미 있으니 잘 배열하면 글이 될 것 같았다.
commitRange: a083c3a..fd2f408
selectedCommits:
- start episode run
- review publish package
- lock publish-ready package
sourceArtifacts:
- public body draft
- publish-ready note
- planning documents
generatedSections:
- 무엇을 말하는 회차인가
- 왜 이 회차가 필요한가
- 읽는 사람에게 남는 것겉으로 보면 필요한 재료가 다 있는 것처럼 보였다. 무엇을 했는지, 어떤 문서를 만들었는지, 어느 시점에 검토하고 잠갔는지가 남아 있었으니까. 하지만 실제 초안을 읽어보면 자꾸 비슷한 느낌이 남았다.
기록은 있었지만, 판단의 장면은 충분히 남아 있지 않았다.

기록은 많은데, 정작 왜 그 판단을 했는지가 잘 보이지 않는 순간. GIF via
GIPHY / CC0 Studios
.
문제는 기록이 부족한 쪽이 아니었다. 오히려 기록은 꽤 많았다. 커밋은 남아 있었고, draft 파일도 있었고, publish-ready note도 있었다. 자동으로 뽑힌 제목과 요약도 그럴듯했다.
예를 들어 초기 draft는 이런 문장을 만들었다.
커밋과 메모를 그대로 쌓는 것만으로는 바깥 사람이 작업 변화를 따라가기 어렵다.
문장 자체는 틀리지 않았다. 하지만 이 문장은 아직 글의 핵심이라기보다 결론에 가까웠다. 읽는 사람 입장에서는 바로 다음 질문이 생긴다.
커밋 로그는 “무엇을 했다”를 남기는 데 강하다. 하지만 “왜 그 순간에 그렇게 판단했는지”는 자주 빠진다. 특히 비교했던 선택지, 버린 방향, 막혔던 이유, 사용자가 했던 정정 같은 것은 커밋 메시지만으로는 거의 복원되지 않았다.
초기 draft에는 review checklist도 있었다. 초안의 모양은 완성됐는데 핵심 항목은 하나도 통과하지 못했다.
reviewChecklist:
core-judgment: false
reason: false
reader-meaning: false
evidence-trail: false
ban-generic-copy: false이 결과는 꽤 정확한 신호였다. 자동으로 글의 모양은 만들 수 있었지만, 좋은 프로젝트 글이 되기 위해 필요한 밀도는 아직 부족했다.
그 부족함은 문장력의 문제가 아니었다. 글을 더 매끄럽게 다듬는다고 해결될 문제가 아니었다. 애초에 source 안에 필요한 장면이 충분히 들어 있지 않았다. 누가 어떤 기준으로 무엇을 선택했는지, 왜 다른 선택지를 버렸는지, 어떤 순간에 방향이 바뀌었는지 같은 재료가 얇았다.
그래서 초안은 자꾸 이런 문장으로 기울었다.
무엇을 말하는 회차인가
왜 이 회차가 필요한가
읽는 사람에게 남는 것구조는 맞지만, 장면이 약했다. 회차는 생겼지만, 독자가 “그래서 그 다음이 궁금하다”고 느낄 만한 구체적인 전환점은 부족했다.
이때 중요한 판단이 하나 생겼다. 콘텐츠 품질이 낮은 이유를 “생성 방식이 아직 부족해서”라고만 보면 안 된다는 점이었다. 물론 생성 방식도 다듬을 수 있다. 제목을 더 좋게 만들고, 문단을 더 자연스럽게 만들고, 이미지를 더 잘 배치할 수도 있다.
하지만 더 앞에 있는 문제는 따로 있었다.
좋은 글은 마지막에 생성되는 것이 아니라, 프로젝트가 진행되는 동안 필요한 재료가 남아 있어야 만들어진다.
이 기준으로 보면, 커밋은 좋은 재료의 일부일 뿐이었다. 커밋은 변화의 흔적을 남긴다. 하지만 프로젝트 콘텐츠에 필요한 것은 변화의 흔적만이 아니었다.
필요했던 것은 조금 더 앞선 기록이었다.
이 네 가지가 남아 있어야 나중에 글을 쓸 때 “결과 보고”가 아니라 “판단의 흐름”을 만들 수 있었다.
이후 방향은 조금 바뀌었다. 커밋과 결과 파일만으로 글을 만들려고 하기보다, 프로젝트가 진행되는 중간에 의미 있는 판단을 짧게 남기는 쪽으로 옮겨갔다. 이때의 기록 단위가 짧은 판단 메모였다.
그 메모는 긴 문서가 아니어도 된다. 오히려 너무 무거우면 프로젝트 진행을 방해한다. 대신 중요한 전환점이 생겼을 때, 나중에 복원하기 어려운 것만 짧게 남기는 방식에 가깝다.
무엇이 바뀌었나
왜 바뀌었나
무엇과 비교했나
나중에 읽는 사람에게 무엇이 달라지나이 정도만 남아도 나중에 글을 쓸 때 출발점이 달라진다. “무엇을 만들었다”에서 시작하지 않고, “왜 이 판단이 필요했나”에서 시작할 수 있기 때문이다.
결국 2회차에서 확인한 것은 커밋의 한계라기보다, 콘텐츠 재료를 바라보는 기준의 변화였다. 커밋은 여전히 중요하다. 하지만 커밋은 마지막 증거에 가깝고, 글을 움직이게 만드는 것은 그 전에 있었던 판단과 비교와 망설임이었다.
다음에는 이 판단이 어떻게 실제 운영 방식으로 바뀌었는지를 다룬다. 프로젝트를 진행하는 대화가 단순 실행 대화가 아니라, 나중에 콘텐츠로 엮일 판단을 포착하는 자리가 된 과정이다.
2026-05-11
최종 화면만 보면 처음부터 그 답을 알고 있었던 것처럼 보인다. 실제로는 그 전에 버린 안, 비교한 기준, 사용자의 정정이 있었다. 좋은 글감은 결과 파일이 아니라 그 중간에 있었다.
커밋만으로 프로젝트 글이 나오지 않는다는 걸 확인한 뒤, 글쓰기보다 source를 먼저 바꿨다. 초안을 매끄럽게 만드는 대신 판단이 살아 있을 때 짧게 붙잡기로 했다.
좋은 글은 마지막에 만들어지는 것이 아니라, 프로젝트가 움직이는 동안 이미 준비된다.
이 판단 때문에 프로젝트 대화 자체를 다시 봤다. 할 일을 정리하는 자리에서, 나중에 콘텐츠가 될 판단이 가장 자주 생기고 있었다.
프로젝트가 끝난 뒤 결과물만 보면 많은 것이 매끈해 보인다. 최종 화면, 최종 문서, 최종 구조만 남으면 마치 처음부터 그 방향이 당연했던 것처럼 보인다. 하지만 실제 작업은 그렇게 진행되지 않는다.
중간에는 늘 이런 순간이 있다.
이런 장면은 커밋 하나로는 잘 남지 않는다. 커밋은 보통 “무엇을 바꿨는가”에 가깝다. 하지만 콘텐츠가 되려면 “왜 그 판단이 생겼는가”가 같이 남아야 했다.
그래서 좋은 재료의 기준을 네 가지로 잡았다.
| 필요한 재료 | 나중에 글에서 하는 역할 |
|---|---|
| 판단 | 무엇을 바꾸거나 하지 않기로 했는지 보여준다 |
| 이유 | 그 선택이 왜 쉬운 결정이 아니었는지 설명한다 |
| 비교 | before/after, option A/B의 차이를 읽게 한다 |
| 장면 | 독자가 그 판단을 눈앞에서 이해하게 만든다 |
이 표가 생기고 나서야, 작업 대화의 역할도 달라졌다. 회의록을 자세히 쓰자는 뜻이 아니었다. 모든 대화를 기록하자는 뜻도 아니었다. 다만 나중에 복원하기 어려운 판단의 순간만큼은 짧게 남기자는 쪽에 가까웠다.
처음부터 모든 프로젝트에 긴 문서를 남기라고 하면 오래가지 못한다. 실제 프로젝트를 진행하는 동안에는 판단하고, 만들고, 고치고, 다시 확인하는 일만으로도 충분히 바쁘다. 콘텐츠를 위해 매번 별도 문서를 길게 쓰기 시작하면, 기록 자체가 또 하나의 일이 된다.
그래서 필요한 것은 큰 문서가 아니라, 짧은 판단 메모였다.
무엇이 바뀌었나
왜 바뀌었나
무엇과 비교했나
나중에 읽는 사람에게 무엇이 달라지나이 정도면 충분한 경우가 많았다. 중요한 것은 길이가 아니라 타이밍이었다. 판단이 막 생긴 직후에는 이유와 비교가 아직 살아 있다. 하지만 시간이 지나면 그때 왜 그렇게 봤는지 흐려진다. 나중에는 최종 결과만 너무 자연스럽게 보이고, 중간의 망설임은 사라진다.

긴 회의록보다 중요한 건, 사라지기 전에 작은 단서를 붙잡는 일에 가까웠다. GIF via GIPHY.
그 짧은 판단 메모는 바로 그 포착을 위한 단위였다. 완성된 글이 아니라, 나중에 글을 가능하게 만드는 최소한의 재료. 그래서 프로젝트를 진행하는 대화가 콘텐츠 생산의 앞단이 되기 시작했다.
이때 AI는 글을 대신 써주는 버튼이라기보다, 흩어진 판단을 다시 펼쳐보고 빠진 맥락을 물어보게 만드는 보조자에 가까웠다. 초안을 빠르게 만들 수 있다는 장점보다 더 중요했던 것은, 사람이 놓친 비교 지점이나 설명의 빈틈을 더 빨리 발견하게 해준다는 점이었다.
그렇다고 작업 중 아무 때나 판단 메모를 남기는 것은 아니다. 너무 자주 남기면 잡음이 많아지고, 너무 늦게 남기면 판단의 온도가 사라진다. 그래서 기준은 전환점에 가까웠다.
예를 들어 이런 순간이다.
특히 덮어써지는 산출물은 중요했다. 같은 파일명이라도 어느 시점에는 슬라이드 2가 한 판단의 근거였고, 나중에는 전혀 다른 내용으로 바뀔 수 있다. 이 경우 파일 경로만 남겨서는 부족하다. 그 판단을 당긴 당시의 상태를 snapshot으로 남겨야 한다.
이 지점에서 프로젝트 대화는 단순한 실행 관리가 아니라, 나중에 글이 어디서 출발했는지를 보존하는 역할도 갖게 됐다.
처음에는 이 모든 것이 콘텐츠 작성 자동화를 잘 만들기 위한 보조 장치처럼 보일 수 있었다. 하지만 실제로는 조금 달랐다. 짧은 판단 메모는 글쓰기 도구라기보다 프로젝트 운영 방식에 가까웠다.
프로젝트가 진행되는 동안 중요한 판단을 더 잘 의식하게 만들고, 왜 그런 선택을 했는지 짧게 남기고, 나중에 다른 사람이 읽을 수 있는 형태로 다시 엮을 수 있게 해준다. 그러면 글은 마지막에 억지로 만들어지는 것이 아니라, 이미 남아 있던 판단의 흔적을 따라 구성된다.
이 변화가 생기고 나서야 ami0iam의 프로젝트 콘텐츠 기능도 조금 더 명확해졌다.
작업 결과
→ 커밋과 산출물
→ 부족한 맥락
→ 작업 중간의 판단 포착
→ 짧은 판단 메모
→ public episode모든 프로젝트를 실시간으로 중계하려는 것은 아니었다. 프로젝트가 지나간 뒤에도 “왜 이 일이 이렇게 흘러갔는지”를 읽으려면, 실행 중간의 작고 중요한 판단부터 잃지 않아야 했다.
이 메모는 완성된 글이 아니었다. 프로젝트가 지나간 뒤에도 판단의 온도를 다시 찾게 해주는 작은 핀에 가까웠다. 다음 문제는 그 핀을 너무 빨리 좋은 것과 나쁜 것으로 나누지 않는 일이었다.
2026-05-11
판단 메모를 좋은 것과 애매한 것으로 나누기 시작했다. 정리는 빨라졌다. 아직 쓰임을 만나지 못한 장면도 함께 닫혔다.
같은 메모가 한 글에서는 운영 잡음이고, 다른 글에서는 가장 중요한 전환점이 될 수 있었다. 그래서 review의 질문을 “쓸 것인가?”에서 “무엇이 있고 무엇이 빠졌는가?”로 바꿨다.
지금은 애매한 재료가, 다른 이야기에서는 가장 중요한 장면이 될 수 있다.
그래서 review의 역할을 다시 잡았다. review는 최종 선별이 아니라, 인벤토리 점검에 가까워야 했다.
짧은 판단 메모는 완성된 글이 아니다. 프로젝트 중간에 생긴 판단의 조각이다. 어떤 메모는 그 자체로 강한 소재처럼 보이고, 어떤 메모는 너무 운영적인 기록처럼 보인다. 하지만 공개할 글을 만들 때는 여러 조각이 서로 연결되면서 의미가 생긴다.
예를 들어 “커밋 기반 실험의 한계”라는 글을 쓸 때 중요한 메모와, “작업 중간의 판단을 남겨야 했던 이유”를 쓸 때 중요한 메모는 다르다. 또 어떤 글에서는 처음엔 운영 메모처럼 보였던 도구 정리나 작업 환경 문제도 중요한 장면이 될 수 있다.
그래서 review 단계에서 너무 빨리 결론을 내리면 위험했다.
| 섣부른 review | 필요한 review |
|---|---|
| 이 메모를 쓸지 말지 결정한다 | 어떤 재료가 있는지 확인한다 |
| confirm/archive로 빨리 나눈다 | 누락·수정·삭제·merge 필요를 본다 |
| 지금 보이는 가치로 판단한다 | 나중의 narrative 가능성을 열어둔다 |
| 콘텐츠 구성을 대신한다 | 콘텐츠 구성을 위한 인벤토리를 정리한다 |
이 차이가 중요했다. review가 너무 강하게 선별하면, 나중에 다른 글을 쓸 때 쓸 수 있었던 재료까지 사라질 수 있다.
그래서 reviewed의 의미도 분리해야 했다. reviewed는 “이 메모가 좋은 콘텐츠 재료로 확정됐다”는 뜻이 아니다. “이 재료는 한 번 검토했고, 현재 상태를 알고 있다”는 표시다.
이 구분이 없으면 같은 재료가 매번 점검 목록에 다시 올라온다. 그러면 점검은 재료 확인이 아니라 반복 확인 작업이 된다. 반대로 reviewed를 확정 표시처럼 써버리면, 아직 다른 방식으로 쓰일 수 있는 재료가 너무 일찍 닫힌다.
reviewed != confirmed
reviewed == checked inventory state즉 점검은 판단 메모를 콘텐츠로 승격시키는 단계가 아니라, 재료 창고를 어지럽지 않게 유지하는 단계였다.

좋은 재료를 고르는 일보다 먼저, 무엇이 있는지 빠뜨리지 않고 확인하는 일이 필요했다. GIF via
GIPHY / University of California
.
review에서 먼저 볼 것은 좋은 메모가 아니라 빠진 재료였다. 한 번은 범위를 잘못 잡아, ami0iam 자체가 아니라 이미 발행된 결과물만 보고 있었다.
사용자의 정정 뒤, 점검 대상은 콘텐츠 수가 아니라 시스템을 바꾼 판단 전환점으로 바뀌었다. 이 경험 때문에 review에는 빠진 항목을 찾는 역할이 더 강하게 들어갔다.
이 질문들이 있어야 review가 단순한 체크리스트를 넘어서게 된다.
결국 재료 점검과 콘텐츠 구성은 다른 일이다. 점검은 재료의 상태를 본다. 구성은 그 재료를 어떤 이야기로 엮을지 결정한다. 하나의 메모가 여러 글에서 다르게 쓰일 수 있다면, 점검이 콘텐츠 구성을 대신하면 안 된다.
이 경계가 생기면서 흐름도 더 분명해졌다.
판단 포착
→ 프로젝트 중간의 판단 조각을 남긴다
재료 점검
→ 무엇이 있고, 무엇이 빠졌는지 확인한다
콘텐츠 구성
→ 가능한 이야기 방향과 회차 구조로 엮는다
페이지 적용
→ 선택한 회차를 실제 /projects 화면에서 읽어본다이렇게 나누고 나서야 짧은 판단 메모가 “선별된 정답 목록”이 아니라 “나중에 여러 방식으로 엮일 수 있는 글감 목록”으로 보이기 시작했다. 프로젝트를 진행하는 세션은 본업을 계속하면서 필요한 순간을 남기고, 별도의 편집 단계는 전체 재료를 보고 콘텐츠 구성을 책임진다.
review는 정답을 고르는 심사대가 아니었다. 나중에 다른 이야기를 만들 수 있도록 재료 창고의 불을 켜두는 일이었다. 다음 단계는 그 창고에서 무엇을 꺼내 어떤 순서로 보여줄지 정하는 일이었다.
2026-05-11
글감은 충분했다. 그래서 글이 산만해졌다.
판단 메모 하나를 회차 하나로 옮기자 정보는 늘고 시리즈의 중심은 흐려졌다. 본문을 더 쓰기 전에, 프로젝트의 도전과 시도, 회차별 질문을 하나의 뼈대로 묶어야 했다.
글을 쓰기 전에, 이 프로젝트가 어떤 문제를 어떤 시도로 풀었는지 먼저 잡아야 했다.
글 하나의 소재보다 프로젝트 전체의 중심 질문이 먼저였다. 이 프로젝트가 어떤 도전 과제를 다루고 있고, 나는 그것을 어떤 방식으로 풀어보려 했는지부터 잡아야 했다.
이 기준이 없으면 회차는 소재 나열이 된다. 메모 하나가 하나의 글이 되고, 또 다른 메모가 다음 글이 된다. 그러면 정보는 많지만 시리즈의 힘은 약해진다.
그래서 먼저 글 전체를 지탱할 중심 흐름, 즉 spine을 잡았다.
project_main_challenge:
이 프로젝트에서 풀기 어려웠던 핵심 문제는 무엇인가
challenge_difficulty:
왜 그 문제가 쉽게 해결되지 않았는가
my_attempt:
나는 그 문제를 어떤 방식으로 풀어보려 했는가
episode_main_question:
이번 회차가 맡을 하나의 질문은 무엇인가
hook_point:
독자가 기억하거나 보고 싶어 할 구체적 장면은 무엇인가이 구조가 생기면 각 회차의 역할이 분명해진다. 어떤 회차는 문제의 출발점을 맡고, 어떤 회차는 도구나 프로토타입을 맡고, 어떤 회차는 실패나 전환을 맡는다. 중요한 것은 모든 것을 한 회차에 다 넣지 않는 것이다.
특히 회차별 후킹 포인트가 중요했다. 프로젝트 글은 쉽게 설명문처럼 변한다. 무엇을 했고, 왜 했고, 어떤 결과가 있었는지 차례로 쓰면 정확할 수는 있지만, 꼭 읽고 싶어지지는 않는다.
그래서 각 회차에는 하나의 강한 hook이 필요했다.
| 회차에서 필요한 것 | 역할 |
|---|---|
| 직접 만든 도구 | “그게 어떻게 생겼지?”라는 궁금증을 만든다 |
| 실패나 복구 장면 | “어떻게 다시 이어갔지?”를 보게 한다 |
| before/after 비교 | 판단이 왜 바뀌었는지 눈으로 읽게 한다 |
| 구체적인 기준 | 추상적인 설명을 실행 가능한 문제로 바꾼다 |
| 외부에서 보기 어려운 운영 방식 | 이 프로젝트만의 관점을 남긴다 |
카카오 제주 임팩트 챌린지의 경우 2회차 후킹 포인트는 “직접 만든 임팩트 계산기”에 가까웠다. 달릴시간에서는 “오늘 몇 시에 달리는 게 좋을까”라는 질문 자체가 hook이 됐다. ami0iam에서는 커밋 기반 실험이 왜 부족했는지, 작업 중간의 판단 기록이 왜 콘텐츠 재료가 되었는지가 후킹 포인트로 잡혔다.

재료를 바로 본문으로 밀어 넣기보다, 먼저 어떤 흐름으로 읽힐지 정리하는 단계가 필요했다. GIF via
GIPHY / Increase Creativity
.
초안을 쓰면서 반복적으로 드러난 문제도 있었다. 중요한 포인트가 추가될수록 글이 단순히 길어지는 경향이었다. 처음에는 빠뜨리지 않는 것이 중요해 보인다. 하지만 계속 더하기만 하면 한 회차가 감당해야 할 범위가 커진다.
그래서 기준을 바꿨다. 새로운 포인트가 생기면 이전 글 위에 그대로 얹는 것이 아니라, 논리 구조를 다시 세워야 했다.
이 기준부터 작성은 분량을 늘리는 일에서 페이지의 읽힘을 조정하는 일로 바뀌었다. 본문, 요약, 프로젝트 소개, 이미지 위치가 따로 놀면 실제 화면에서 바로 어색해졌다.
이 과정에서 이미지 기준도 바뀌었다. 처음에는 이미지가 있으면 좋은 보조 요소처럼 보였다. 하지만 긴 프로젝트 글에서는 이미지가 없으면 화면이 답답해진다. 반대로 아무 이미지나 넣으면 글의 신뢰도가 떨어진다.
그래서 기준은 조금 더 복잡해졌다.
1. 실제 프로젝트 산물을 먼저 본다.
2. 하지만 품질이 낮거나 낡았으면 쓰지 않는다.
3. 적절한 산물이 없으면 관련 외부 밈/GIF를 찾는다.
4. 생성 이미지는 최후 수단으로 둔다.
5. 긴 글인데 이미지가 없으면 visual_gap으로 표시한다.프로젝트 콘텐츠는 과정의 밀도가 높다. 독자가 중간에 숨을 쉬고 어떤 장면을 보는지 붙잡으려면 이미지도 제 역할을 해야 했다. 좋은 이미지는 장식이 아니라 읽는 구조의 일부였다.
마지막으로 바뀐 것은 draft의 위치였다. 예전에는 글 초안만 잘 쓰면 된다고 생각하기 쉽다. 하지만 실제 판단은 /projects 화면에서 이루어진다. 프로젝트 overview, 회차 카드, 본문, 이미지가 함께 보일 때 글의 느낌이 달라지기 때문이다.
그래서 최종 단계는 글 파일만 만드는 단계가 아니라 실제 페이지에 적용해 보는 단계가 됐다. 선택한 콘텐츠 구조를 실제 로컬 페이지에 적용하고, 그 화면에서 읽어보며 판단한다.
구성: 어떤 이야기와 회차 구조가 가능한가
작성: 선택한 회차가 실제 페이지에서 읽히는가이 구분이 생기면서 ami0iam의 콘텐츠 시스템도 한 번 더 정리됐다. 프로젝트 중간의 판단은 짧게 남기고, 점검 단계는 글감 목록을 관리하고, 구성 단계는 구조를 제안하고, 작성 단계는 실제 페이지에서 읽히는 상태로 만든다.
목표는 글을 자동으로 많이 뽑는 일이 아니었다. 사라지기 쉬운 판단을 붙잡고, 각 장면이 맡을 일을 정하고, 실제 화면에서 끝까지 읽히게 만드는 일이었다. 글감은 재료였고, spine은 그 재료가 길을 잃지 않게 하는 뼈대였다.
강의 / 프로그램
WHY
참여팀이 자기 활동의 변화를 직접 설명하고 다음 실행에 쓸 수 있게 만들 수 없을까? 임팩트는 평가표에 적는 말이 아니라, 협력과 지원을 얻기 위해 팀이 스스로 꺼내야 하는 근거였습니다. 다만 활동 중에 꾸준히 다루기에는 너무 멀고 무겁게 느껴졌습니다.
HOW
측정을 요구하기보다, 자기 활동을 설명해보는 연습으로 낮췄습니다. 참여팀이 부담 없이 활동을 숫자와 문장으로 다시 읽어볼 수 있도록 계산기와 실행 템플릿을 함께 설계했습니다.
WHAT
강의, 임팩트 계산기, OKR·마일스톤 템플릿을 하나의 흐름으로 연결했습니다. 활동 유형을 고르고 몇 가지 질문에 답하면 변화 가능성을 연습용으로 시뮬레이션하고, 그 결과를 다음 실행 기준으로 옮길 수 있게 했습니다.
2026-05-09
카카오 제주 임팩트 챌린지에서 세 팀의 전담 멘토링을 맡았다. 이어 임팩트 측정 강의 요청이 들어왔다.
지표와 측정 방법부터 설명할 수 있었다. 하지만 계속 만날 팀들에게 먼저 필요한 것은 방법론의 순서가 아니었다. 이미 좋은 활동을 하고도 다음 지원과 협력을 요청할 때 왜 말이 막히는지부터 풀어야 했다.
좋은 활동이 다음 기회로 이어지려면, 그 활동이 만든 변화를 말할 수 있어야 했다.
실제 강의 자료의 첫 장. “좋은 활동이 만든 변화를 더 잘 바라보고, 더 편하게 설명하고, 다음 기회로 이어지게 하는 방법”에서 출발했다.
소셜 섹터에서 임팩트 관리는 늘 중요하게 말해진다. 운영기관에는 좋은 활동이 어떤 변화를 만들었는지 설명할 근거가 필요하다. 그래야 다음 지원이나 협력도 설계할 수 있다.
하지만 이건 운영기관만의 필요는 아니다. 활동하는 팀에게도 임팩트는 더 좋은 협력과 지원을 얻어내는 강력한 무기가 될 수 있다. 우리가 어떤 변화를 만들고 있는지 말할 수 있을 때, 필요한 자원을 더 구체적으로 요청할 수 있고 파트너에게 함께해야 할 이유도 더 분명하게 제안할 수 있기 때문이다.
문제는 그 무기가 활동 중에는 멀게 느껴진다는 데 있다.
그래서 관리는 뒤로 밀린다. 그러다 막상 협력이나 지원이 필요한 시점이 오면, 좋은 활동은 있었지만 그것을 설명할 말과 근거가 부족해지는 상황이 반복된다.
이번 강의의 출발점은 이 간격이었다. 참여팀은 이미 무언가를 하고 있는 팀들이었다. 그래서 “임팩트란 무엇인가”를 먼저 설명하기보다, “좋은 활동인데 왜 설명이 어려울까”에서 시작하는 편이 맞다고 봤다.
먼저 다뤄야 했던 것은 이런 순간들이었다.
그래서 강의 초반의 프레임은 지원·협력·성장으로 잡혔다. 작은 활동이 더 큰 움직임이 되려면 지원이 필요하고, 협력이 필요하고, 계속 나아지기 위한 성장이 필요하다. 그리고 이 세 가지는 활동의 좋은 의도만으로 생기지 않는다. 활동이 만든 변화를 읽을 수 있어야 생긴다.

실제 강의 자료에서는 지원·협력·성장을 이어가기 위한 공통 언어로 임팩트 관리를 배치했다.
이때 임팩트 관리는 평가 기술이라기보다 설명의 힘에 가까워졌다. 참여자에게 “측정해야 합니다”라고 말하는 것이 아니라, 이렇게 묻는 쪽에 가까웠다.
이미 하고 있는 좋은 활동이 더 잘 읽히려면 어떤 설명이 필요할까?
이 전환이 중요했다. 임팩트를 관리한다는 말이 보고서나 평가표의 언어로만 남으면, 참여자는 그것을 자기 활동의 다음 기회와 연결하기 어렵다. 반대로 내가 만든 변화가 무엇인지 설명할 수 있고, 그 설명으로 필요한 지원을 요청하고, 함께할 파트너를 설득하고, 다음 실행을 바꿀 수 있다면 임팩트 관리는 훨씬 가까운 일이 된다.
하지만 질문만 바꾼다고 충분한 것은 아니었다. 방향은 잡혔지만, 실제로 참여자가 자기 활동을 어떻게 임팩트 언어로 옮겨볼 수 있을지는 여전히 막막할 수 있었다.
그래서 다음으로 필요했던 것은 손에 잡히는 장치였다. 복잡한 평가 보고서가 아니라, 자기 활동을 넣어보면서 몇 가지 질문에 답해볼 수 있는 도구.
방향은 설명에서 잡았지만, 참여자가 자기 활동을 직접 옮겨볼 손잡이는 아직 없었다. 그래서 다음 강의에는 평가표 대신 계산기를 가져갔다.
2026-05-10
QR을 열면 활동 유형과 다섯 개의 입력칸이 나왔다. 값을 바꾸면 연습용 임팩트 추정치가 바로 움직였다.
“임팩트를 측정해야 합니다”라는 설명만으로는 참여팀의 손이 움직이지 않았다. 자기 활동 앞에서는 여전히 어렵고 부담스럽고, 우리 일은 숫자에 맞지 않는다는 감각이 먼저 올라왔다.
이 저항은 틀렸다고 설득해서 사라지는 것이 아니었다. 실제로 임팩트 측정은 연구, 조사, 분석, 보고서 같은 단어와 쉽게 연결된다. 활동을 실행하기도 바쁜 팀에게는 또 하나의 업무처럼 느껴질 수 있다. 모든 변화를 숫자로 바꿀 수 없다는 감각도 맞다.
그래서 이번에는 “측정해야 합니다”라고 더 강하게 말하는 대신, 먼저 부담을 낮추는 장치가 필요했다. 완벽한 평가 보고서를 쓰자는 것이 아니라, 자기 활동의 일부 변화를 가볍게 확인해보는 경험. 임팩트 관리를 멀리 있는 방법론이 아니라 지금 하는 활동 옆에 놓을 수 있는 연습으로 바꾸고 싶었다.
그 고민 끝에 강의 안에 임팩트 계산기를 넣었다. 이 계산기는 강의 흐름에 맞춰 직접 만든 작은 웹 도구였다. 참여자가 QR로 접속해 활동 유형을 고르고, 몇 가지 입력값을 바꿔보면 연습용 임팩트 추정치가 어떻게 달라지는지 바로 확인할 수 있게 했다.
계산기의 뼈대는 완전히 새로운 공식이라기보다, 임팩트 평가에서 이미 쓰이는 개념들을 강의 상황에 맞게 낮춘 것이었다. 숫자를 임의로 만들고 싶지는 않았지만, 그렇다고 엄밀한 평가 모델을 그대로 가져와 참여팀의 부담을 키우고 싶지도 않았다.
계산기는 세 관점을 낮춰 썼다. 변화 흐름은 Theory of Change와 Logic Model에서, 과장 보정은 SROI에서, 기여 관점은 Contribution Analysis에서 가져왔다.
정리하면 계산기에 반영한 것은 이 정도였다.
참고: Carol H. Weiss, “Nothing as Practical as Good Theory”(1995); James P. Connell & Anne C. Kubisch, “Applying a Theory of Change Approach to the Evaluation of Comprehensive Community Initiatives”(1998); W.K. Kellogg Foundation, Logic Model Development Guide(2004); Jeremy Nicholls, Eilis Lawlor, Eva Neitzert & Tim Goodspeed, A Guide to Social Return on Investment(2012); John Mayne, “Addressing Attribution through Contribution Analysis”(2001).
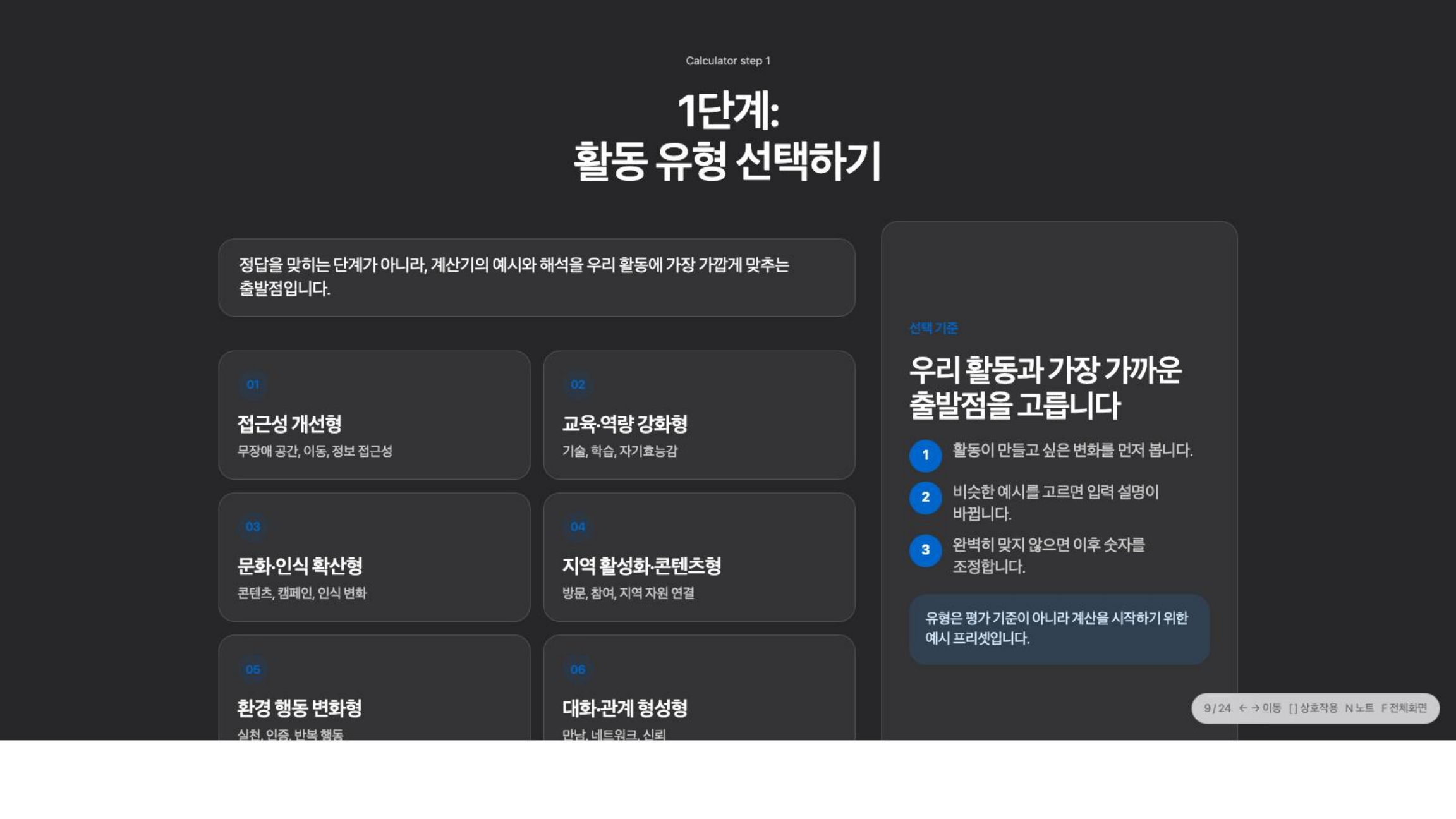
계산기는 정답을 맞히는 도구가 아니라, 자기 활동과 가장 가까운 출발점을 고르는 방식으로 시작하도록 설계했다.
계산기를 만든다고 해서 임팩트가 갑자기 정확해지는 것은 아니다. 오히려 이 도구의 목적은 정밀한 산출보다 진입장벽을 낮추는 데 있었다. 참여팀이 “우리 활동은 측정이 어렵다”에서 멈추지 않고, “우리 활동의 일부 변화는 이렇게 말해볼 수 있겠다”까지 가보는 것이 중요했다.
그래서 입력 구조도 최대한 단순하게 잡았다. 복잡한 지표 체계나 평가 용어를 먼저 꺼내기보다, 현장에서 바로 떠올릴 수 있는 다섯 개의 입력값으로 바꿨다.
계산은 단순 참여자 수를 세는 방식이 아니다.
도달 인원 × 변화 발생률 × 변화 단계 × 기여 변화율 × (1 - 자연 변화율)확인된 변화에 깊이와 기여도를 반영하고, 과장될 수 있는 부분을 보수적으로 덜어내는 구조다. 이 정도라면 완벽한 조사 설계가 없어도 시작할 수 있다. 신청자 수와 실제 참여자 수를 구분하고, 활동 후의 짧은 확인 질문을 남기고, 반복 방문이나 인증 같은 기존 운영 기록을 활용하는 것만으로도 첫 번째 추정은 가능해진다.
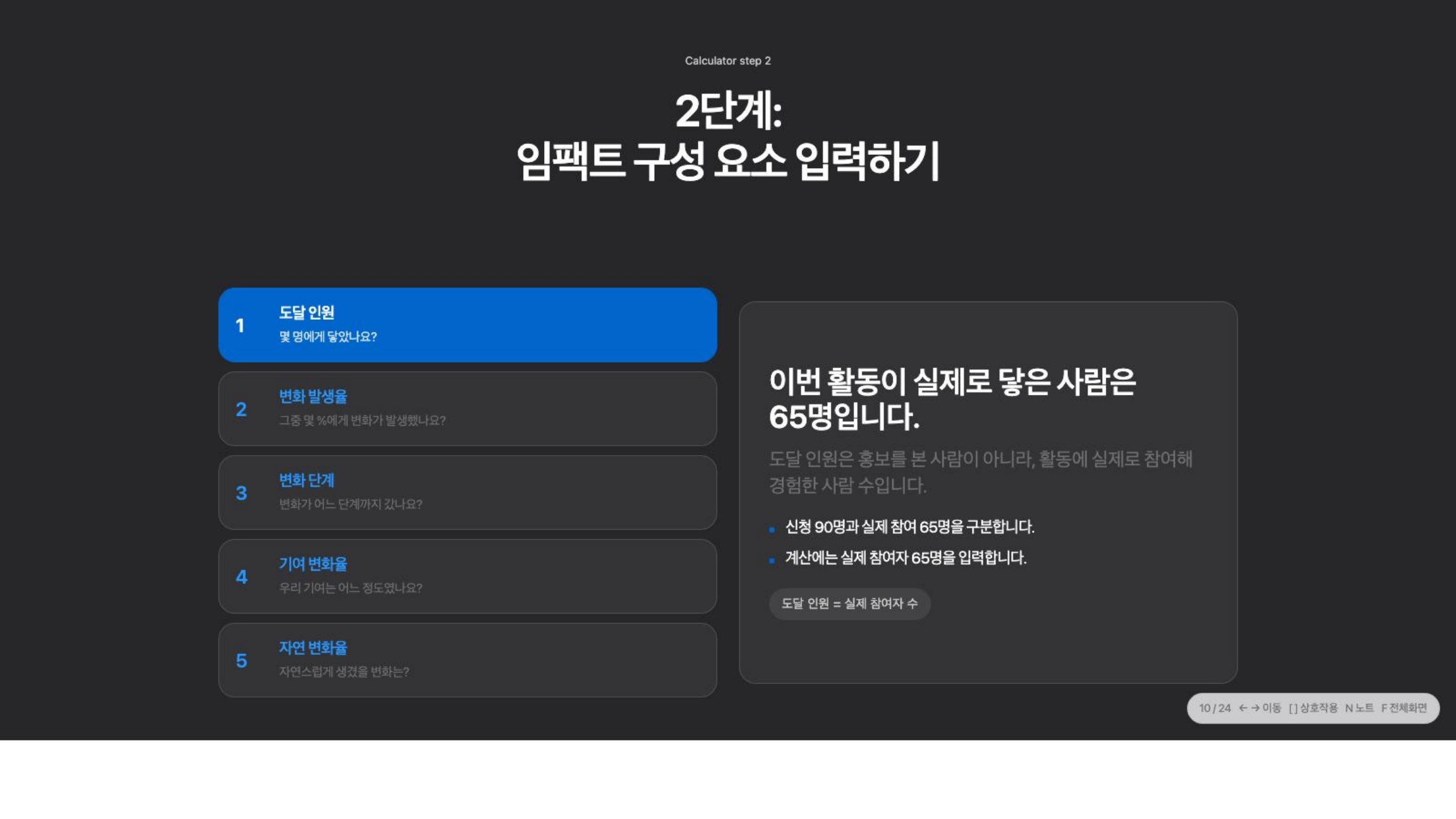
계산기는 전문 용어보다 다섯 개의 입력값을 먼저 보여준다. 숫자는 완성된 평가가 아니라, 활동을 다시 설명해보는 출발점이다.
또 하나 중요했던 것은 예시의 순서였다. 처음에는 특정 팀 사례를 바로 보여주는 방식도 생각할 수 있었다. 하지만 낯선 팀 이름이 앞에 오면, 참여자는 “저 사례는 그 팀 이야기”라고 느끼고 자기 활동으로 옮겨오기가 어려울 수 있다.
그래서 팀 이름보다 활동 유형을 먼저 두었다.
활동의 성격을 먼저 고르고, 그 다음에 비슷한 사례를 참고하도록 했다. 완벽하게 맞는 분류를 찾는 것이 아니라, 자기 활동과 가장 가까운 출발점을 고르는 방식이다.
이렇게 하면 계산기는 평가표보다 대화의 도구에 가까워진다.
“우리 활동은 이 유형에 가까운데, 도달 인원은 누구로 봐야 할까?”
“변화가 발생했다고 볼 수 있는 신호는 무엇일까?”
“우리 역할을 너무 크게 잡고 있지는 않을까?”
숫자는 결론이 아니라, 질문을 더 구체적으로 만드는 매개가 된다.
계산기 사용 전에는 각 입력값을 어떤 기준으로 볼지 먼저 정리했다. 숫자보다 중요한 것은 무엇을 숫자로 볼지 합의하는 일이었다.
이 과정에서 계속 조심한 것은 계산기를 너무 똑똑한 도구처럼 보이게 하지 않는 것이었다. 임팩트 계산기는 “우리 점수”를 판정하는 장치가 아니다. 좋은 활동의 가치를 숫자 하나로 줄이려는 도구도 아니다.
오히려 역할은 반대에 가깝다.
그 정도의 가벼운 시작이 필요했다.
임팩트 관리는 무겁게 시작하면 계속 미뤄진다. 하지만 너무 가볍게만 다루면 다음 실행으로 이어지지 않는다. 그래서 계산기는 그 사이에 놓인 장치였다. 참여자가 부담 없이 입력해볼 수 있을 만큼 단순하지만, 입력하고 나면 자기 활동을 조금 더 구체적으로 바라보게 만드는 도구.
계산기는 정답을 내는 기계가 아니라 대화를 시작하는 손잡이였다. 다만 숫자를 한 번 보고 닫으면 흥미로운 실습으로 끝난다. 다음 단계에서는 결과 점수가 아니라 그 점수를 만든 다섯 입력값을 OKR과 30/60/90일 계획으로 옮겼다.
2026-05-11
계산기에는 임팩트 추정치가 나왔다. 그 숫자를 그대로 목표 칸에 옮기면 계산기는 다시 성적표가 된다.
그래서 결과값은 두고, 그 값을 만든 입력을 옮겼다. 도달 인원, 변화 발생률, 변화 단계, 기여 변화율, 자연 변화율은 다음 실행을 설계할 질문이 될 수 있었다.
숫자는 결론이 아니라 다음 계획의 재료여야 했다.
그래서 마지막 단계에서는 계산 결과 자체보다, 그 숫자를 만든 입력값을 OKR 시트로 옮기는 흐름을 만들었다. 임팩트 추정치를 그대로 목표로 삼으면 “몇 점을 만들 것인가”라는 질문으로 좁아질 수 있다. 하지만 입력값을 보면 질문이 달라진다.
이 질문들은 바로 Objective와 Key Result의 재료가 된다. 도달 인원은 참여 규모 KR로, 변화 발생률은 핵심 변화 KR로, 변화 단계는 목표값을 해석하는 기준으로, 기여·자연 변화는 운영 기록이나 멘토링 메모에 남길 근거로 옮길 수 있다.

강의에서는 임팩트 추정치 자체보다, 지수를 만든 입력값을 KR의 지표명·단위·현재/목표 값으로 바꾸는 흐름을 보여줬다.
이 전환이 중요했다. 계산기에서 나온 숫자는 한 번 보고 지나갈 수 있지만, 입력값을 KR로 옮기면 활동의 다음 기준이 된다. “얼마나 했는가”보다 “어떤 변화가 확인되면 다음 단계로 갈 수 있는가”를 묻게 되기 때문이다.
OKR 시트에 바로 활동명을 쓰면 실행 목록은 생기지만, 변화의 방향은 흐려질 수 있다. 그래서 Objective에는 활동명이 아니라 프로젝트를 통해 달라지길 바라는 상태를 쓰도록 했다.
예를 들어 재사용 컵 챌린지라면 목표는 “챌린지를 운영한다”가 아니라 이런 문장에 가까웠다.
참여자가 2주 동안 재사용 컵을 실제 생활에서 반복 사용하도록 만든다.
이 문장을 다시 보면, 계산기의 입력값이 어디에 붙는지 보인다.
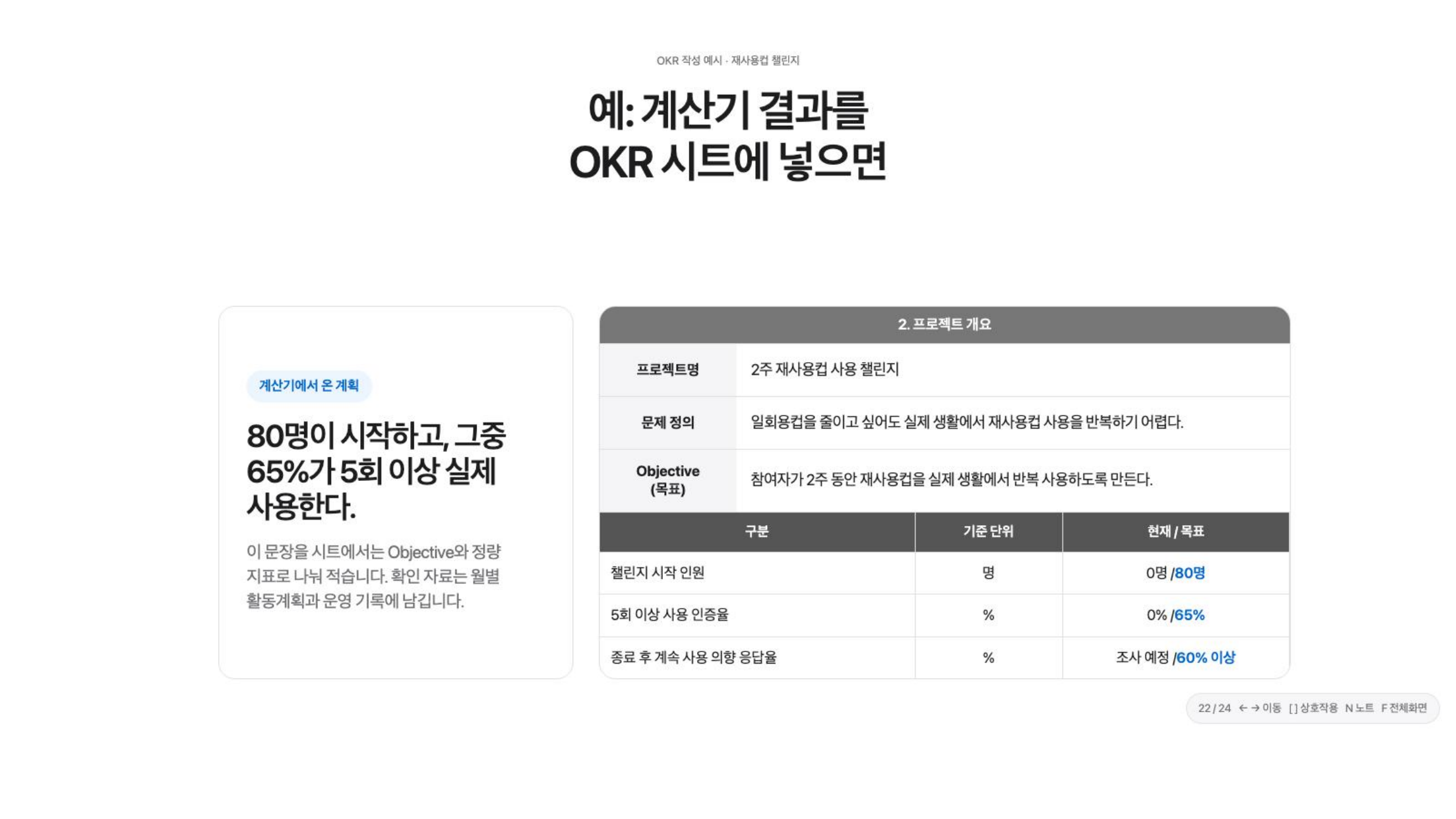
숫자를 시트에 옮길 때는 “지수”보다 “지수를 만든 입력값”을 Objective와 KR로 나눠 적는 쪽이 더 실용적이었다.
이렇게 옮기면 계산기는 성적표가 아니라 계획을 선명하게 만드는 도구가 된다. 목표 문장은 변화의 방향을 잡고, KR은 그 변화가 일어났는지 확인할 숫자를 남긴다. 그리고 확인 자료는 월별 활동계획과 운영 기록 안에 남기면 된다.
마지막으로 연결해야 했던 것은 마일스톤이었다. 좋은 KR을 써도, 그 숫자를 만들기 위한 활동이 언제 어떻게 배치되는지 없으면 계획은 다시 추상적으로 남는다.
그래서 마일스톤은 거창한 로드맵보다 실행 순서를 잡는 표에 가깝게 다뤘다. 특히 처음에는 큰 활동 단위만 적어도 충분하다고 봤다.
재사용 컵 챌린지 예시에서는 신청서와 기존 사용 빈도 문항을 먼저 설계하고, 키트 수령 명단과 인증 방식을 준비하고, 실제 챌린지를 운영한 뒤, 5회 이상 인증률과 계속 사용 의향을 정리하는 식으로 월별 흐름을 잡았다.
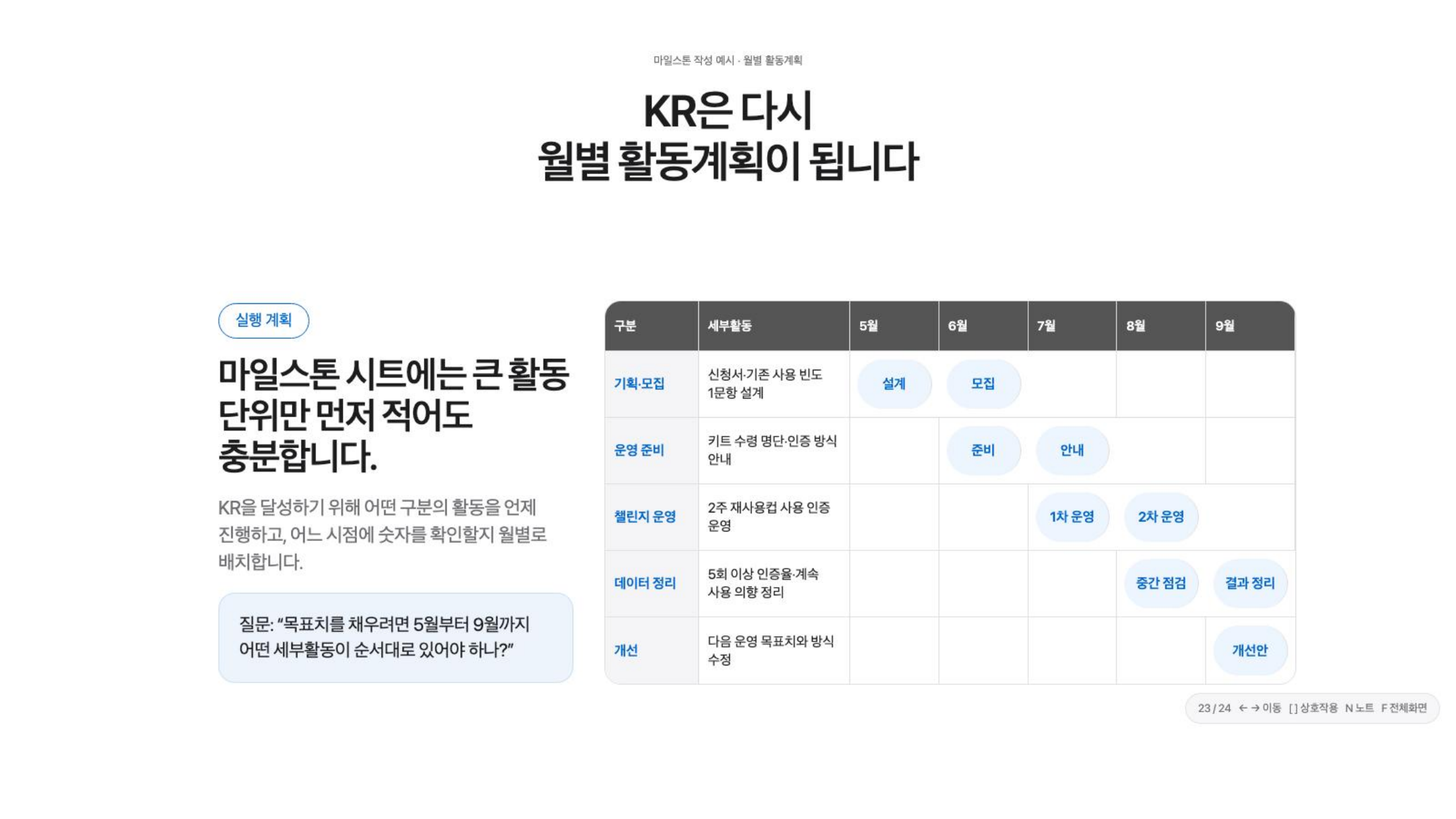
마일스톤은 완벽한 일정표라기보다, KR을 달성하기 위해 어떤 활동을 언제 진행하고 어느 시점에 숫자를 확인할지 배치하는 도구로 썼다.
여기까지 오면 임팩트 관리는 평가의 언어에서 조금 벗어난다. 처음에는 좋은 활동을 왜 설명해야 하는지에서 시작했고, 다음에는 그 설명을 어렵지 않게 해보려고 계산기를 만들었다. 마지막에는 계산기의 숫자를 다시 OKR과 마일스톤으로 옮겼다.
정리하면 강의에서 만들고 싶었던 흐름은 이랬다.
좋은 활동을 설명해야 하는 이유
→ 부담을 낮추는 계산기
→ 계산기의 입력값
→ OKR과 마일스톤
→ 다음 실행하고 싶었던 일은 임팩트를 더 어렵게 증명하는 것이 아니었다. 이미 하는 활동에서 변화의 신호를 찾고, 그 숫자를 다음 행동에 옮기는 일이었다.
점수는 한 번 보고 닫을 수 있다. 입력값이 KR과 일정이 되면, 좋은 활동은 다음 지원을 설명하는 숫자에서 다음 변화를 만드는 계획으로 넘어간다.